## Radar Chart: Performance Comparison of Pythia-1B and PonderingPythia-1B
### Overview
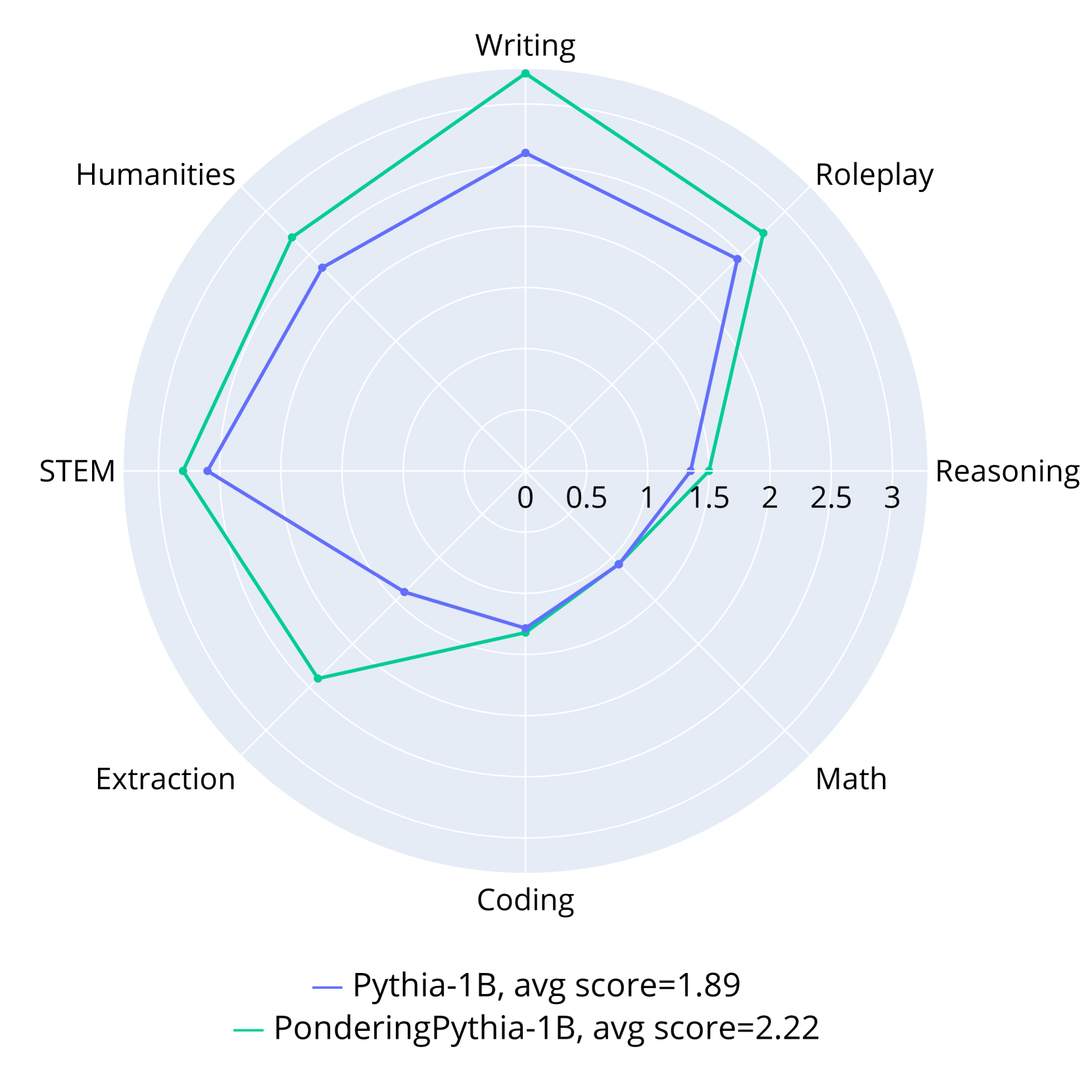
The image is a radar chart comparing the performance of two language models, **Pythia-1B** (blue line) and **PonderingPythia-1B** (green line), across eight categories: **Writing, Roleplay, Reasoning, Math, Coding, Extraction, STEM, Humanities**. The chart uses a circular layout with radial axes scaled from 0 to 3. The legend at the bottom identifies the models by color, and average scores are provided: Pythia-1B (1.89) and PonderingPythia-1B (2.22).
---
### Components/Axes
- **Axes (Categories)**:
- **Writing** (top)
- **Roleplay** (top-right)
- **Reasoning** (right)
- **Math** (bottom-right)
- **Coding** (bottom)
- **Extraction** (bottom-left)
- **STEM** (left)
- **Humanities** (top-left)
- **Legend**:
- **Pythia-1B**: Blue line (avg score = 1.89)
- **PonderingPythia-1B**: Green line (avg score = 2.22)
- **Scale**: Radial axes range from 0 to 3, with increments of 0.5.
---
### Detailed Analysis
#### Pythia-1B (Blue Line)
- **Writing**: ~2.0
- **Roleplay**: ~2.0
- **Reasoning**: ~1.5
- **Math**: ~1.0
- **Coding**: ~1.0
- **Extraction**: ~1.5
- **STEM**: ~2.0
- **Humanities**: ~2.0
#### PonderingPythia-1B (Green Line)
- **Writing**: ~3.0
- **Roleplay**: ~2.5
- **Reasoning**: ~1.5
- **Math**: ~2.0
- **Coding**: ~2.0
- **Extraction**: ~2.5
- **STEM**: ~3.0
- **Humanities**: ~2.5
---
### Key Observations
1. **PonderingPythia-1B outperforms Pythia-1B in most categories**:
- **STEM** and **Writing** show the largest gaps (3.0 vs. 2.0 for both).
- **Extraction** (2.5 vs. 1.5) and **Humanities** (2.5 vs. 2.0) also favor PonderingPythia-1B.
2. **Shared weaknesses**:
- Both models score lowest in **Math** and **Coding** (1.0 for Pythia-1B, 2.0 for PonderingPythia-1B).
3. **Reasoning**: Both models score similarly (~1.5), suggesting this is a shared limitation.
4. **Average scores**: PonderingPythia-1B’s higher average (2.22 vs. 1.89) confirms its overall superiority.
---
### Interpretation
- **Performance Trends**:
PonderingPythia-1B demonstrates stronger capabilities in **STEM** and **Writing**, likely due to enhanced reasoning or domain-specific training. Its performance in **Math** and **Coding** improves moderately compared to Pythia-1B, but both models struggle in these areas, indicating a potential gap in computational task handling.
- **Reasoning as a Bottleneck**:
The similar low scores in **Reasoning** (~1.5 for both) suggest this is a critical area for improvement across models.
- **Implications**:
PonderingPythia-1B’s higher average score (2.22) positions it as a more versatile model, particularly for tasks requiring **STEM** expertise or **Writing** proficiency. However, both models require optimization in **Math** and **Coding** to address fundamental weaknesses.
---
### Spatial Grounding & Verification
- **Legend Position**: Bottom-center, clearly associating colors with models.
- **Color Consistency**: Blue (Pythia-1B) and green (PonderingPythia-1B) lines match the legend without ambiguity.
- **Axis Placement**: Categories are evenly spaced around the radar, with **Writing** at the top and **Math** at the bottom-right.
### Uncertainties
- Exact values are approximate due to the absence of gridlines or numerical labels on the radial axes.
- The chart does not specify confidence intervals or error margins for the scores.