\n
## Bar Chart: Accuracy vs. KV Cache Length for Different Models
### Overview
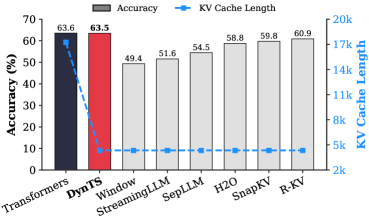
This image presents a bar chart comparing the accuracy and KV cache length of several models: Transformers, DynTS, Window StreamingLLM, SepLLM, H2O, SnapKV, and R-KV. Accuracy is represented by the height of the bars, while KV cache length is indicated by a dashed line with markers.
### Components/Axes
* **X-axis:** Model names (Transformers, DynTS, Window StreamingLLM, SepLLM, H2O, SnapKV, R-KV).
* **Y-axis (left):** Accuracy (%) - Scale ranges from 0 to 70.
* **Y-axis (right):** KV Cache Length (k) - Scale ranges from 2k to 20k.
* **Legend:**
* Gray bars: Accuracy
* Blue dashed line with markers: KV Cache Length
* **Data Series:**
* Accuracy for each model.
* KV Cache Length for each model.
### Detailed Analysis
The chart displays the following data:
* **Transformers:** Accuracy ≈ 63.6%, KV Cache Length ≈ 63.6k.
* **DynTS:** Accuracy ≈ 63.5%, KV Cache Length ≈ 5k.
* **Window StreamingLLM:** Accuracy ≈ 49.4%, KV Cache Length ≈ 5k.
* **SepLLM:** Accuracy ≈ 51.6%, KV Cache Length ≈ 5k.
* **H2O:** Accuracy ≈ 54.5%, KV Cache Length ≈ 5k.
* **SnapKV:** Accuracy ≈ 58.8%, KV Cache Length ≈ 5k.
* **R-KV:** Accuracy ≈ 59.8%, KV Cache Length ≈ 5k.
**Trends:**
* Accuracy generally increases from Window StreamingLLM to R-KV, with a significant jump from Window StreamingLLM to SepLLM.
* KV Cache Length remains relatively constant at approximately 5k for all models except Transformers and DynTS.
* Transformers and DynTS have significantly higher accuracy than the other models, but also have much larger KV Cache Lengths.
### Key Observations
* Transformers and DynTS exhibit the highest accuracy, but at the cost of a substantially larger KV cache length.
* The remaining models (Window StreamingLLM, SepLLM, H2O, SnapKV, R-KV) have similar KV cache lengths, but varying levels of accuracy.
* There is a clear trade-off between accuracy and KV cache length.
### Interpretation
The data suggests that achieving high accuracy in these models requires a larger KV cache. However, the other models demonstrate that reasonable accuracy can be achieved with a significantly smaller cache size. This could be important in resource-constrained environments where memory is limited.
The large difference in KV cache length between Transformers/DynTS and the other models indicates a different architectural approach or optimization strategy. Transformers and DynTS may store more information in the KV cache to achieve higher accuracy, while the other models prioritize efficiency.
The relatively flat KV cache length across most models suggests that this parameter may be limited by a system constraint or design choice, rather than being directly optimized for each model. The accuracy differences within this constraint show the effectiveness of different model architectures.
The data points to a potential area for further research: exploring methods to reduce the KV cache length of high-accuracy models like Transformers without significantly sacrificing performance.