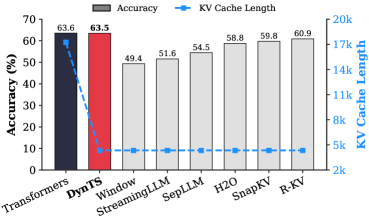
## Bar Chart: Model Performance Comparison
### Overview
The chart compares the accuracy and KV cache length of various language models (LMs) on a classification task. It uses grouped bars for accuracy (%) and a dashed line for KV cache length, with models listed on the x-axis.
### Components/Axes
- **X-axis**: Model names (Transformers, DynTS, Window StreamingLLM, SepLLM, H2O, SnapKV, R-KV)
- **Y-axis (left)**: Accuracy (%) ranging from 0 to 70
- **Y-axis (right)**: KV Cache Length ranging from 2k to 20k
- **Legend**:
- Gray bars: Accuracy (%)
- Blue dashed line: KV Cache Length
- **Positioning**:
- Legend: Top center
- Blue dashed line: Overlaid on bars, spanning all x-axis categories
### Detailed Analysis
- **Accuracy (%)**:
- Transformers: 63.6%
- DynTS: 63.5%
- Window StreamingLLM: 49.4%
- SepLLM: 51.6%
- H2O: 54.5%
- SnapKV: 58.8%
- R-KV: 59.8%
- **KV Cache Length**:
- Constant at ~10k across all models (blue dashed line)
### Key Observations
1. **Accuracy Variance**:
- Transformers and DynTS achieve the highest accuracy (63.6% and 63.5%, respectively), with a negligible 0.1% difference.
- Other models show significantly lower accuracy, with Window StreamingLLM at the lowest (49.4%).
2. **KV Cache Consistency**:
- All models maintain identical KV cache length (~10k), indicating no trade-off between cache efficiency and accuracy in this dataset.
3. **Performance Gradient**:
- Accuracy decreases from Transformers/DynTS to Window StreamingLLM, then gradually improves through H2O, SnapKV, and R-KV.
### Interpretation
The data suggests that KV cache length is not a limiting factor for accuracy in this benchmark, as all models maintain the same cache efficiency. The stark accuracy gap between Transformers/DynTS and other models implies architectural or training differences rather than resource constraints. The near-identical performance of Transformers and DynTS highlights potential optimization opportunities for newer models. Notably, the absence of a clear correlation between cache length and accuracy challenges assumptions about hardware-software co-design trade-offs in LLM deployment.