## Line Chart: Accuracy vs. Number of Samples
### Overview
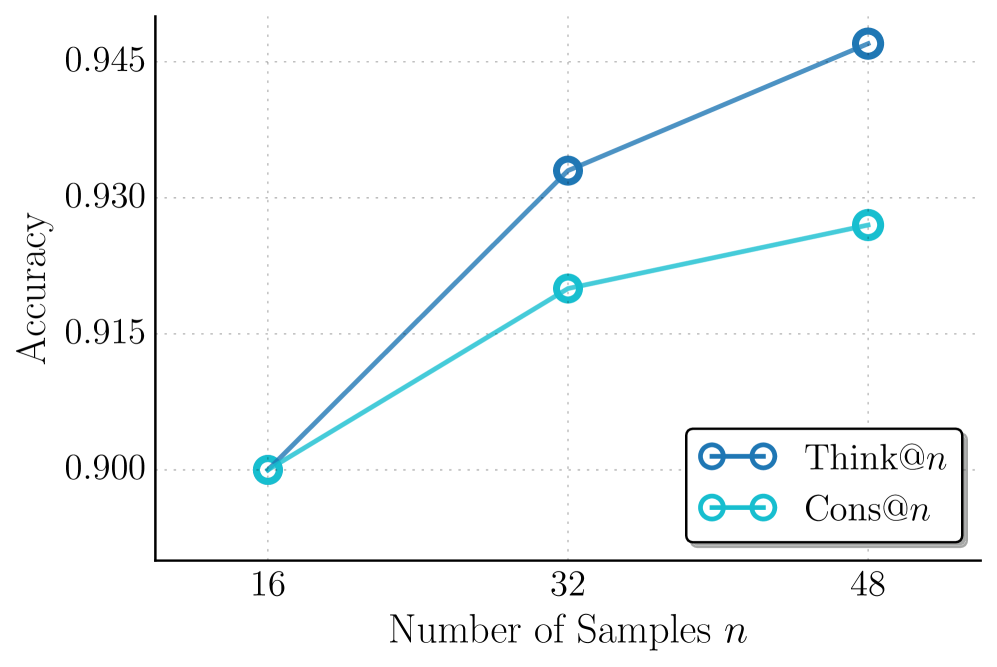
The image is a line chart comparing the accuracy of two methods, "Think@n" and "Cons@n", as the number of samples (n) increases. The x-axis represents the number of samples, and the y-axis represents the accuracy.
### Components/Axes
* **X-axis:** Number of Samples *n*. Values: 16, 32, 48.
* **Y-axis:** Accuracy. Values: 0.900, 0.915, 0.930, 0.945.
* **Legend:** Located in the bottom-right corner.
* "Think@n": Represented by a dark blue line with circle markers.
* "Cons@n": Represented by a light blue line with circle markers.
### Detailed Analysis
* **Think@n (Dark Blue):**
* Trend: The accuracy increases as the number of samples increases.
* Data Points:
* At 16 samples, the accuracy is approximately 0.900.
* At 32 samples, the accuracy is approximately 0.931.
* At 48 samples, the accuracy is approximately 0.946.
* **Cons@n (Light Blue):**
* Trend: The accuracy increases as the number of samples increases, but at a slower rate compared to "Think@n".
* Data Points:
* At 16 samples, the accuracy is approximately 0.900.
* At 32 samples, the accuracy is approximately 0.917.
* At 48 samples, the accuracy is approximately 0.928.
### Key Observations
* Both methods show an increase in accuracy with an increasing number of samples.
* "Think@n" consistently outperforms "Cons@n" in terms of accuracy across all sample sizes.
* The rate of increase in accuracy for "Think@n" appears to be higher than that of "Cons@n", especially between 16 and 32 samples.
### Interpretation
The chart suggests that increasing the number of samples improves the accuracy of both "Think@n" and "Cons@n" methods. However, "Think@n" demonstrates a higher accuracy and a more significant improvement with increasing samples compared to "Cons@n". This implies that "Think@n" might be a more effective method for the given task, especially when a larger number of samples is available. The initial equal accuracy at 16 samples suggests that both methods perform similarly with limited data, but "Think@n" leverages additional data more effectively.