\n
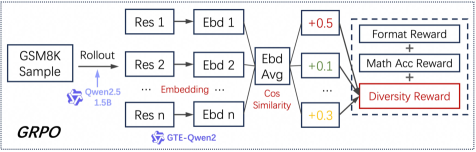
## Diagram: GRPO System Architecture
### Overview
The image depicts a diagram illustrating the architecture of a system named "GRPO". The system takes a "GSM8K Sample" as input and processes it through a series of steps involving "Rollout", "Res" (presumably representing responses), "Ebd" (presumably representing embeddings), and reward calculations. The diagram highlights the flow of information and the weighting of different reward components.
### Components/Axes
The diagram consists of the following key components:
* **Input:** "GSM8K Sample" (top-left)
* **Model:** "Qwen2.5 1.5B" (connected to "Rollout")
* **Response Generation:** "Rollout"
* **Response Blocks:** "Res 1" to "Res n" (multiple blocks in a vertical sequence)
* **Embedding Blocks:** "Ebd 1" to "Ebd n" (corresponding to each "Res" block)
* **Embedding Aggregation:** "Ebd Avg" (aggregates embeddings from "Ebd 1" to "Ebd n")
* **Similarity Calculation:** "Cos Similarity" (calculates cosine similarity)
* **Reward Weights:** "+0.5", "+0.1", "+0.3" (weights applied to different reward components)
* **Reward Components:** "Format Reward", "Math Acc Reward", "Diversity Reward" (rewards used for system optimization)
* **Model:** "GTE-Qwen2" (connected to "Embedding...")
* **System Identifier:** "GRPO" (bottom-left)
### Detailed Analysis or Content Details
The diagram shows a process flow starting with a "GSM8K Sample". This sample is fed into a "Rollout" process powered by the "Qwen2.5 1.5B" model. The "Rollout" generates multiple responses, labeled "Res 1" through "Res n". Each response is then converted into an embedding, labeled "Ebd 1" through "Ebd n". These embeddings are aggregated into "Ebd Avg", and then used to calculate "Cos Similarity".
The "Cos Similarity" output is then used to calculate weighted rewards. The weights are:
* "+0.5" for "Format Reward"
* "+0.1" for "Math Acc Reward"
* "+0.3" for "Diversity Reward"
The "Diversity Reward" component is highlighted with a dashed red border. The "Embedding..." block is connected to the "GTE-Qwen2" model.
### Key Observations
* The system appears to prioritize "Format Reward" as it has the highest weight (0.5).
* "Diversity Reward" is visually emphasized, suggesting its importance in the system's design.
* The diagram shows a parallel processing structure with multiple "Res" and "Ebd" blocks, indicating the system generates and evaluates multiple responses.
* The diagram does not provide specific numerical data beyond the reward weights.
### Interpretation
The diagram illustrates a Reinforcement Learning (RL) framework for generating responses to GSM8K problems. The system uses a large language model ("Qwen2.5 1.5B") to generate multiple responses ("Rollout"). These responses are then evaluated based on three criteria: format, mathematical accuracy, and diversity. The weights assigned to each reward component suggest that the system prioritizes generating well-formatted responses, followed by diversity, and then mathematical accuracy. The use of embeddings and cosine similarity suggests that the system is evaluating the semantic similarity between generated responses, potentially to encourage diversity. The dashed red border around "Diversity Reward" indicates that this aspect is a key focus of the GRPO system. The "GTE-Qwen2" model is likely used for embedding generation. The overall architecture suggests a system designed to generate high-quality, diverse, and accurate solutions to mathematical problems.