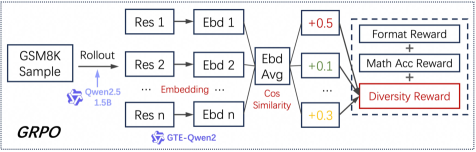
## Flowchart: GSM8K Response Generation and Reward System
### Overview
The diagram illustrates a technical workflow for processing GSM8K (Grade School Math 8K) samples through a response generation pipeline, embedding analysis, and reward calculation system. It combines elements of natural language processing (NLP) and reinforcement learning concepts.
### Components/Axes
1. **Left Section (Input/Processing):**
- **GSM8K Sample**: Starting point for math problem input
- **Rollout**: Process generating multiple responses (Res 1 to Res n)
- **Embeddings (Ebd 1 to Ebd n)**: Vector representations of responses
- **Embedding Average**: Aggregated representation of all response embeddings
- **Cosine Similarity**: Measures diversity between response vectors
2. **Right Section (Output/Rewards):**
- **Reward Calculation Block**: Contains three weighted reward components:
- Format Reward (+0.5 weight)
- Math Accuracy Reward (+0.1 weight)
- Diversity Reward (+0.3 weight, highlighted in red)
3. **Model Components:**
- **Qwen2.5 1.5B**: Model architecture used for response generation
- **GTE-Qwen2**: Embedding model for response vectorization
### Detailed Analysis
- **Response Generation Flow**:
GSM8K samples → Rollout process → Multiple responses (Res 1 to Res n) → Embeddings (Ebd 1 to Ebd n)
- **Embedding Analysis**:
- Embeddings are averaged to create a composite representation
- Cosine similarity calculations determine response diversity (values shown as +0.5, +0.1, +0.3)
- **Reward System**:
- Format Reward (0.5 weight): Likely evaluates response structure/clarity
- Math Accuracy Reward (0.1 weight): Assesses correctness of mathematical solutions
- Diversity Reward (0.3 weight): Prioritizes varied response generation (highlighted in red)
### Key Observations
1. The Diversity Reward receives the highest weight (0.3) despite being lower than Format Reward (0.5), suggesting a balance between solution variety and presentation quality
2. Cosine similarity values (+0.5, +0.1, +0.3) indicate moderate to high similarity between response embeddings
3. The red highlighting of Diversity Reward emphasizes its importance in the optimization process
4. Multiple response generation (Res 1 to Res n) suggests a beam search or sampling approach
### Interpretation
This system appears designed to optimize educational response generation by:
1. Balancing solution accuracy with response diversity
2. Using embedding similarity to quantify response variation
3. Implementing a weighted reward system that values diverse solutions (0.3) more than mathematical accuracy alone (0.1)
4. Prioritizing format quality (0.5) while maintaining diversity
The architecture suggests a reinforcement learning approach where responses are evaluated through both direct metrics (format, accuracy) and indirect measures (embedding diversity). The emphasis on diversity reward indicates an intent to prevent model collapse toward single solution patterns, which is particularly important in educational contexts where multiple valid solution paths exist.