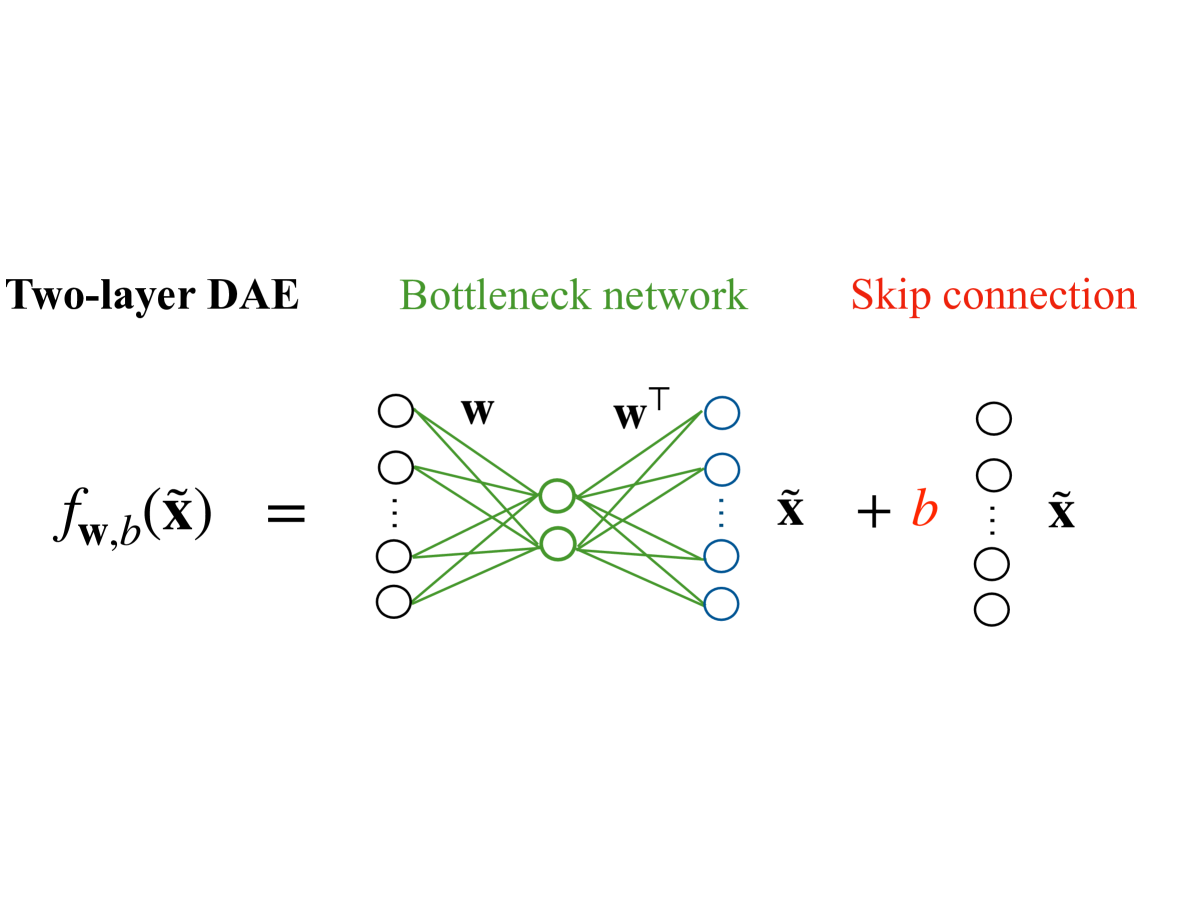
## Diagram: Two-layer Denoising Autoencoder (DAE) with Skip Connection
### Overview
The image is a technical diagram illustrating the architecture of a two-layer Denoising Autoencoder (DAE) that incorporates a skip connection. It visually decomposes the model's function into two primary components: a central "Bottleneck network" and a parallel "Skip connection." The diagram uses color-coding and mathematical notation to define the model's operation.
### Components/Axes
The diagram is organized into three distinct horizontal sections, each with a label at the top:
1. **Left Section (Black Label):** "Two-layer DAE"
* Contains the mathematical definition of the model's function: \( f_{\mathbf{w},b}(\tilde{\mathbf{x}}) = \)
2. **Center Section (Green Label):** "Bottleneck network"
* Depicts a neural network with three layers of nodes (circles).
* **Input Layer (Left):** Four black circles arranged vertically, with a vertical ellipsis (`⋮`) between the second and third circles, indicating an arbitrary number of input nodes.
* **Hidden/Bottleneck Layer (Center):** Two green circles.
* **Output Layer (Right):** Four blue circles arranged vertically, with a vertical ellipsis (`⋮`) between the second and third circles.
* **Connections:** Green lines connect all input nodes to all hidden nodes, and all hidden nodes to all output nodes.
* **Weight Labels:** The connections from input to hidden are labeled with a bold **`w`**. The connections from hidden to output are labeled with a bold **`w`** with a superscript T (**`wᵀ`**), indicating the transpose of the weight matrix.
* The output of this sub-network is labeled **`x̃`** (x with a tilde).
3. **Right Section (Red Label):** "Skip connection"
* Depicts a vertical column of four black circles with a vertical ellipsis (`⋮`) between the second and third circles, mirroring the input layer's structure.
* A red plus sign (`+`) and a red italicized **`b`** are positioned between the output of the bottleneck network and this column of nodes.
* The final output of the entire system, to the right of the skip connection nodes, is labeled **`x̃`**.
### Detailed Analysis
The diagram explicitly defines the function \( f_{\mathbf{w},b}(\tilde{\mathbf{x}}) \) as the sum of two terms:
1. The output of the **Bottleneck network**, which processes the input **`x̃`** through a hidden layer using weight matrices **`w`** and **`wᵀ`**.
2. A **Skip connection** term, which consists of a learnable bias vector **`b`** added to the original input **`x̃`**.
**Spatial Grounding & Component Isolation:**
* The **legend/labels** are positioned directly above their corresponding components: "Two-layer DAE" (top-left), "Bottleneck network" (top-center), "Skip connection" (top-right).
* The **mathematical equation** flows from left to right, aligning with the visual components.
* The **color coding** is consistent: Green is used for the "Bottleneck network" label and its internal connections/hidden nodes. Red is used for the "Skip connection" label and the bias term **`b`**. Black is used for the primary function label, input/output nodes, and the final output symbol.
### Key Observations
* **Weight Tying:** The use of **`w`** for the encoder (input-to-hidden) and **`wᵀ`** (the transpose) for the decoder (hidden-to-output) indicates a "tied weights" architecture, a common technique in autoencoders to reduce parameters and enforce symmetry.
* **Skip Connection Nature:** The skip connection is not a direct identity pass-through of the input. Instead, it adds a bias term **`b`** to the input **`x̃`**. This is a specific architectural choice, differing from a simple residual connection that would add the raw input **`x̃`** itself.
* **Input/Output Notation:** The input and final output are both denoted as **`x̃`**, suggesting the model's goal is to reconstruct its (possibly noisy) input.
### Interpretation
This diagram illustrates a specific variant of a denoising autoencoder designed for representation learning. The core function is performed by the **bottleneck network**, which compresses the input **`x̃`** into a lower-dimensional hidden representation (the two green nodes) and then attempts to reconstruct it. The tied weights (**`w`** and **`wᵀ`**) impose a constraint that often leads to more robust features.
The **skip connection** adds a learned bias **`b`** to the original input before it is combined with the bottleneck network's output. This can help the model learn a residual correction or adjust the baseline of the reconstruction task. The overall architecture suggests a model that learns to extract essential features through compression while retaining a mechanism to directly modulate the input signal via the bias term. This could be useful for tasks where preserving certain global properties of the input is as important as learning its latent features.