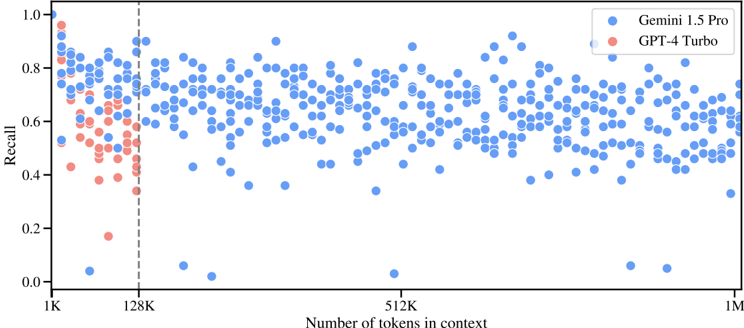
## Scatter Plot: Recall vs. Number of Tokens in Context
### Overview
The image is a scatter plot comparing the recall performance of Gemini 1.5 Pro and GPT-4 Turbo models against the number of tokens in context. The x-axis represents the number of tokens in context, ranging from 1K to 1M. The y-axis represents the recall, ranging from 0.0 to 1.0. Each dot represents a data point for a specific number of tokens in context and its corresponding recall value. Gemini 1.5 Pro is represented by blue dots, and GPT-4 Turbo is represented by red dots. A vertical dashed line is present at 128K tokens in context.
### Components/Axes
* **Title:** (Implicit) Recall vs. Number of Tokens in Context
* **X-axis:**
* Label: Number of tokens in context
* Scale: 1K, 128K, 512K, 1M (logarithmic scale)
* **Y-axis:**
* Label: Recall
* Scale: 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
* **Legend:** Located in the top-right corner.
* Blue dot: Gemini 1.5 Pro
* Red dot: GPT-4 Turbo
* **Vertical Dashed Line:** Located at 128K tokens in context.
### Detailed Analysis
* **Gemini 1.5 Pro (Blue):**
* Trend: The recall values are generally high, mostly above 0.6, and relatively consistent across the range of tokens in context. There is a slight decrease in recall as the number of tokens increases, but it is not substantial.
* Data Points:
* At 1K tokens, recall ranges from approximately 0.7 to 0.9.
* At 128K tokens, recall ranges from approximately 0.5 to 0.9.
* At 512K tokens, recall ranges from approximately 0.5 to 0.9.
* At 1M tokens, recall ranges from approximately 0.5 to 0.8.
* **GPT-4 Turbo (Red):**
* Trend: The recall values are lower than Gemini 1.5 Pro, and the data points are concentrated in the lower range of recall values, especially before the 128K token mark. After 128K, there are no data points for GPT-4 Turbo.
* Data Points:
* At 1K tokens, recall ranges from approximately 0.4 to 0.7.
* At 128K tokens, recall ranges from approximately 0.2 to 0.6.
* **Vertical Dashed Line (128K):**
* Marks a clear distinction in the data, as GPT-4 Turbo data points are only present before this line.
### Key Observations
* Gemini 1.5 Pro consistently outperforms GPT-4 Turbo in terms of recall across the tested context lengths.
* GPT-4 Turbo's performance data is only available for context lengths up to 128K tokens.
* The recall for Gemini 1.5 Pro remains relatively stable as the number of tokens in context increases.
* There is a noticeable drop in GPT-4 Turbo's recall as the number of tokens approaches 128K.
### Interpretation
The scatter plot suggests that Gemini 1.5 Pro is more effective at recalling information across a wide range of context lengths compared to GPT-4 Turbo. The absence of GPT-4 Turbo data points beyond 128K tokens implies that either the model was not tested or its performance was not satisfactory for longer context lengths. The vertical line at 128K tokens serves as a visual separator, highlighting the context length where GPT-4 Turbo's data ends. The data indicates that Gemini 1.5 Pro maintains a more consistent and higher recall performance, making it a potentially more reliable model for tasks requiring long-context understanding.