\n
## Scatter Plot: Recall vs. Number of Tokens in Context
### Overview
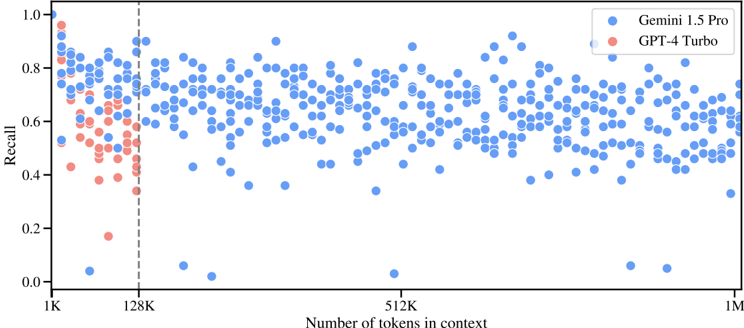
This image presents a scatter plot comparing the Recall performance of two language models, Gemini 1.5 Pro and GPT-4 Turbo, as a function of the number of tokens in the context window. The plot displays a large number of data points for each model, allowing for a visual assessment of their performance trends.
### Components/Axes
* **X-axis:** Number of tokens in context. Scale is logarithmic, with markers at 1K, 128K, 512K, and 1M (1 million).
* **Y-axis:** Recall. Scale ranges from 0.0 to 1.0.
* **Legend:** Located in the top-right corner.
* Blue circles: Gemini 1.5 Pro
* Red circles: GPT-4 Turbo
* **Vertical dashed line:** Positioned at 128K tokens on the x-axis. This line likely indicates a significant change or threshold in the models' performance.
### Detailed Analysis
The plot shows a large number of data points for both models.
**Gemini 1.5 Pro (Blue):**
The data points for Gemini 1.5 Pro are scattered across the plot. The trend appears relatively stable, with a slight downward slope as the number of tokens increases.
* At 1K tokens, Recall values range approximately from 0.55 to 0.95.
* At 128K tokens, Recall values range approximately from 0.4 to 0.8.
* At 512K tokens, Recall values range approximately from 0.4 to 0.75.
* At 1M tokens, Recall values range approximately from 0.3 to 0.7.
There are a few outliers with very low Recall values (close to 0.0) at higher token counts.
**GPT-4 Turbo (Red):**
The data points for GPT-4 Turbo are concentrated primarily to the left of the 128K marker. The trend shows a clear downward slope.
* At 1K tokens, Recall values range approximately from 0.5 to 0.85.
* At 128K tokens, Recall values range approximately from 0.1 to 0.6.
* Beyond 128K tokens, there are very few data points for GPT-4 Turbo.
### Key Observations
* Gemini 1.5 Pro maintains a more consistent Recall performance across a wider range of token counts compared to GPT-4 Turbo.
* GPT-4 Turbo's Recall performance degrades significantly as the number of tokens increases, with very limited data available beyond 128K tokens.
* The vertical dashed line at 128K tokens appears to mark a point where GPT-4 Turbo's performance drops off considerably.
* Gemini 1.5 Pro exhibits some low Recall outliers at the highest token counts, suggesting potential challenges in maintaining performance with very long contexts.
### Interpretation
The data suggests that Gemini 1.5 Pro is more robust to increasing context window sizes than GPT-4 Turbo. Gemini 1.5 Pro demonstrates a relatively stable Recall performance even with a large number of tokens in the context, while GPT-4 Turbo's performance deteriorates rapidly beyond 128K tokens. The vertical line at 128K likely represents a limitation in GPT-4 Turbo's ability to effectively process longer contexts. The scatter plot highlights the importance of context window size in language model performance and suggests that Gemini 1.5 Pro has a significant advantage in handling long-range dependencies. The outliers for Gemini 1.5 Pro at 1M tokens could indicate areas for further optimization or suggest that even with a robust architecture, very long contexts can still pose challenges for maintaining high Recall.