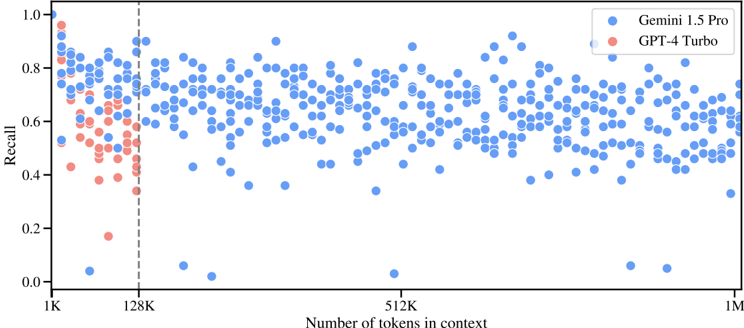
## Scatter Plot: Recall vs. Context Length for Gemini 1.5 Pro and GPT-4 Turbo
### Overview
This image is a scatter plot comparing the performance (Recall) of two large language models, Gemini 1.5 Pro and GPT-4 Turbo, as a function of the number of tokens in the context window. The plot uses a logarithmic scale for the x-axis. Data for Gemini 1.5 Pro spans the entire context range shown, while data for GPT-4 Turbo is confined to the left portion of the graph.
### Components/Axes
* **Chart Type:** Scatter Plot.
* **X-Axis:**
* **Label:** "Number of tokens in context"
* **Scale:** Logarithmic.
* **Major Tick Marks/Labels:** 1K, 128K, 512K, 1M.
* **Y-Axis:**
* **Label:** "Recall"
* **Scale:** Linear, from 0.0 to 1.0.
* **Major Tick Marks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0.
* **Legend:** Located in the top-right corner.
* **Blue Circle:** "Gemini 1.5 Pro"
* **Red Circle:** "GPT-4 Turbo"
* **Key Visual Element:** A vertical dashed gray line is positioned at the 128K token mark on the x-axis.
### Detailed Analysis
**Data Series & Trends:**
1. **GPT-4 Turbo (Red Circles):**
* **Spatial Grounding:** All data points are located to the left of the vertical 128K dashed line.
* **Trend Verification:** The data shows a general downward trend in Recall as the number of tokens increases from 1K towards 128K. The points are densely clustered between 1K and ~64K tokens.
* **Data Points (Approximate):** Recall values start high (near 1.0 at ~1K tokens) and decline, with most points falling between 0.4 and 0.8 in the 1K-64K range. There are notable low outliers: one point near 0.18 Recall at ~32K tokens, and another near 0.35 Recall at ~128K tokens. No data points are present for GPT-4 Turbo beyond the 128K mark.
2. **Gemini 1.5 Pro (Blue Circles):**
* **Spatial Grounding:** Data points are distributed across the entire x-axis, from 1K to 1M tokens, on both sides of the 128K dashed line.
* **Trend Verification:** There is no strong, singular linear trend. The Recall values show high variance (scatter) at all context lengths but remain broadly distributed, primarily between 0.4 and 0.9.
* **Data Points (Approximate):**
* **1K - 128K Range:** Recall values are densely scattered, mostly between 0.5 and 0.9, with some points as low as ~0.05.
* **128K - 512K Range:** The scatter continues, with a similar range (0.4 - 0.9). A few low outliers exist near 0.05 and 0.35.
* **512K - 1M Range:** The density of points appears slightly lower, but the range of Recall values remains consistent (approx. 0.4 - 0.85), with a few points near 0.05 and 0.3.
### Key Observations
1. **Context Length Limit:** The vertical dashed line at 128K tokens and the absence of red points to its right strongly suggest that the evaluated version of GPT-4 Turbo has a maximum context window of 128K tokens, while Gemini 1.5 Pro is tested up to 1M tokens.
2. **Performance Distribution:** Gemini 1.5 Pro maintains a broad distribution of Recall scores across its entire tested context range (1K to 1M tokens). There is no obvious, consistent degradation in performance as context length increases to 1M tokens based on this visual scatter.
3. **GPT-4 Turbo Trend:** Within its operational range (up to 128K), GPT-4 Turbo shows a visible negative correlation between context length and Recall.
4. **Outliers:** Both models exhibit occasional very low Recall scores (~0.05) at various context lengths, which may represent specific failure cases or challenging test samples.
### Interpretation
This chart visually benchmarks the "needle-in-a-haystack" or retrieval capabilities of two leading LLMs across long contexts. The key takeaway is the contrast in tested capability: Gemini 1.5 Pro is demonstrated to function with measurable Recall across a 1-million-token context, whereas GPT-4 Turbo's data is confined to a 128K window.
The data suggests that while GPT-4 Turbo's recall performance tends to decrease as its context fills up to its 128K limit, Gemini 1.5 Pro's performance, though variable, does not show a clear visual trend of degradation up to 1M tokens. The high variance for both models indicates that recall accuracy is highly dependent on the specific content and position of the information within the context, not just the total length. The presence of near-zero recall outliers for both models highlights that even advanced models can completely fail to retrieve information under certain conditions, regardless of context length. This plot emphasizes context window size as a critical differentiator and shows that a larger window does not automatically guarantee perfect recall, but provides the *opportunity* for retrieval across vast amounts of text.