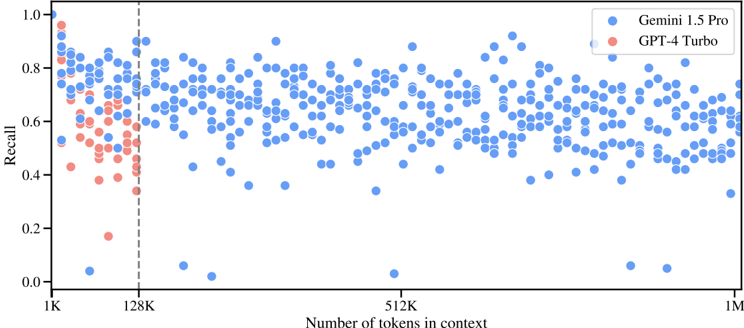
## Scatter Plot: Recall vs. Context Length for Gemini 1.5 Pro and GPT-4 Turbo
### Overview
This scatter plot compares the recall performance of two AI models (Gemini 1.5 Pro and GPT-4 Turbo) across varying context lengths (number of tokens in context). The x-axis represents context length (1K to 1M tokens), and the y-axis represents recall (0.0 to 1.0). Data points are color-coded: blue for Gemini 1.5 Pro and red for GPT-4 Turbo.
### Components/Axes
- **X-axis**: "Number of tokens in context" (logarithmic scale: 1K, 128K, 512K, 1M)
- **Y-axis**: "Recall" (linear scale: 0.0 to 1.0)
- **Legend**: Located in the top-right corner, with blue representing Gemini 1.5 Pro and red representing GPT-4 Turbo.
- **Vertical dashed line**: At 128K tokens on the x-axis.
### Detailed Analysis
1. **GPT-4 Turbo (Red Points)**:
- Concentrated in the lower-left quadrant (1K–128K tokens).
- Recall values range from ~0.2 to ~0.8, with most points below 0.6.
- Sharp decline in recall as context length increases beyond 128K tokens.
- No red points observed beyond 128K tokens.
2. **Gemini 1.5 Pro (Blue Points)**:
- Distributed across all context lengths (1K–1M tokens).
- Recall values range from ~0.4 to ~0.8, with higher density in the 0.6–0.8 range.
- Notable clustering in the 512K–1M token range, suggesting improved performance at larger contexts.
- A single blue outlier at ~0.0 recall near 1K tokens.
### Key Observations
- **Performance Threshold**: GPT-4 Turbo’s recall drops sharply at 128K tokens, with no data points beyond this threshold.
- **Scalability**: Gemini 1.5 Pro maintains higher recall across larger contexts, particularly in the 512K–1M range.
- **Outliers**: One anomalous blue point at ~0.0 recall near 1K tokens, potentially indicating an edge case or data error.
### Interpretation
The data suggests **Gemini 1.5 Pro outperforms GPT-4 Turbo in handling longer contexts**, with recall rates remaining stable or improving as context length increases. GPT-4 Turbo’s performance degrades significantly beyond 128K tokens, possibly due to architectural limitations or training data constraints. The vertical dashed line at 128K tokens may represent a critical threshold where GPT-4 Turbo’s recall becomes unreliable. Gemini’s broader distribution of high-recall points (0.6–0.8) across larger contexts highlights its robustness in real-world applications requiring extensive context processing. The single low-recall outlier for Gemini warrants further investigation to rule out data anomalies.