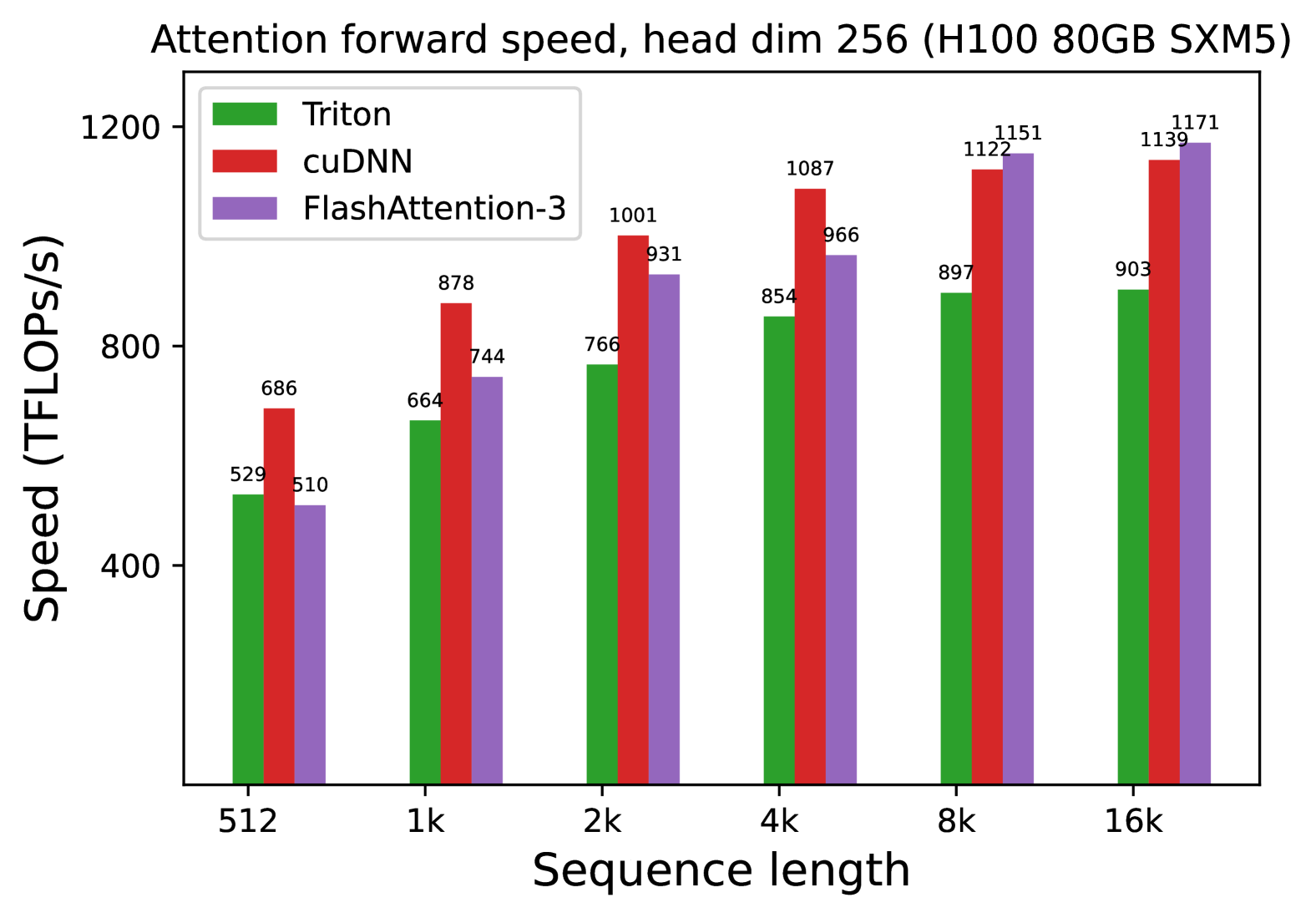
# Technical Document Extraction: Attention Forward Speed Benchmark
## 1. Header Information
* **Title:** Attention forward speed, head dim 256 (H100 80GB SXM5)
* **Subject:** Performance benchmarking of different attention implementations on NVIDIA H100 GPU hardware.
## 2. Chart Metadata
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis Label:** Speed (TFLOPS/s)
* **Y-Axis Scale:** Linear, ranging from 400 to 1200 with major ticks at 400, 800, and 1200.
* **X-Axis Label:** Sequence length
* **X-Axis Categories:** 512, 1k, 2k, 4k, 8k, 16k.
* **Legend Location:** Top-left
* **Legend Categories:**
* **Triton:** Green bar
* **cuDNN:** Red bar
* **FlashAttention-3:** Purple bar
## 3. Component Isolation & Data Extraction
### Trend Verification
* **Triton (Green):** Shows a consistent upward trend as sequence length increases, starting at 529 and plateauing around 900 TFLOPS/s.
* **cuDNN (Red):** Shows a strong upward trend, consistently outperforming Triton. It peaks at 1139 TFLOPS/s at the 16k sequence length.
* **FlashAttention-3 (Purple):** Shows the most significant growth curve. While it starts as the slowest at 512, it scales better than the others, eventually overtaking cuDNN at the 8k and 16k marks to become the fastest implementation.
### Data Table Reconstruction
The following table represents the precise numerical values labeled above each bar in the chart.
| Sequence Length | Triton (Green) | cuDNN (Red) | FlashAttention-3 (Purple) |
| :--- | :--- | :--- | :--- |
| **512** | 529 | 686 | 510 |
| **1k** | 664 | 878 | 744 |
| **2k** | 766 | 1001 | 931 |
| **4k** | 854 | 1087 | 966 |
| **8k** | 897 | 1122 | 1151 |
| **16k** | 903 | 1139 | 1171 |
## 4. Technical Observations
* **Scaling Efficiency:** FlashAttention-3 demonstrates superior scaling for long sequences (8k+). At 16k, it reaches the highest recorded throughput of **1171 TFLOPS/s**.
* **Small Sequence Performance:** For shorter sequences (512 to 4k), cuDNN maintains a performance lead over both Triton and FlashAttention-3.
* **Hardware Context:** These benchmarks are specific to the **H100 80GB SXM5** architecture with a **head dimension of 256**. Performance characteristics may vary on different hardware or with different head dimensions.