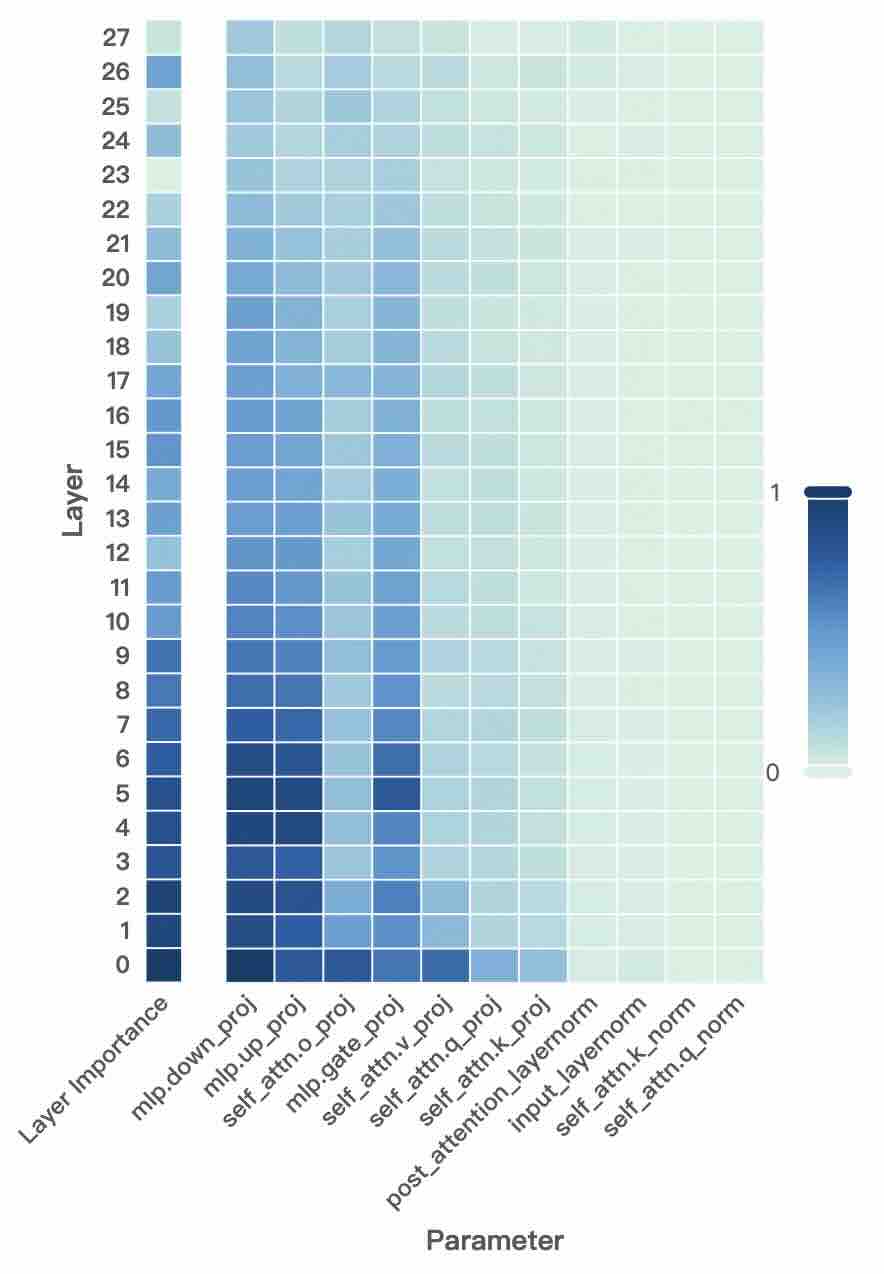
## Heatmap: Layer Importance vs. Parameter
### Overview
The image is a heatmap visualizing the importance of different layers in a neural network with respect to various parameters. The heatmap uses a blue-to-green color gradient, where darker blue indicates higher importance and lighter green indicates lower importance. The y-axis represents the layer number (0-27), and the x-axis represents different parameters within the network.
### Components/Axes
* **Y-axis:** "Layer" with numerical labels from 0 to 27, incrementing by 1. Also includes the label "Layer Importance" at the bottom of the y-axis.
* **X-axis:** "Parameter" with the following labels:
* mlp.down\_proj
* mlp.up\_proj
* self\_attn.o\_proj
* mlp.gate\_proj
* self\_attn.v\_proj
* self\_attn.q\_proj
* self\_attn.k\_proj
* post\_attention\_layernorm
* input\_layernorm
* self\_attn.k\_norm
* self\_attn.q\_norm
* **Color Legend:** Located on the right side of the heatmap. Dark blue corresponds to a value of 1, and light green corresponds to a value of 0. The color gradient represents values between 0 and 1.
### Detailed Analysis or ### Content Details
The heatmap shows the relative importance of each layer (0-27) for each parameter.
* **mlp.down\_proj:** Layers 0-14 are dark blue, indicating high importance. Layers 15-27 transition to lighter shades of blue, indicating decreasing importance.
* **mlp.up\_proj:** Layers 0-14 are dark blue, indicating high importance. Layers 15-27 transition to lighter shades of blue, indicating decreasing importance.
* **self\_attn.o\_proj:** Layers 0-14 are dark blue, indicating high importance. Layers 15-27 transition to lighter shades of blue, indicating decreasing importance.
* **mlp.gate\_proj:** Layers 0-7 are dark blue, indicating high importance. Layers 8-14 transition to lighter shades of blue, indicating decreasing importance. Layers 15-27 transition to light green, indicating low importance.
* **self\_attn.v\_proj:** Layers 0-7 are dark blue, indicating high importance. Layers 8-14 transition to lighter shades of blue, indicating decreasing importance. Layers 15-27 transition to light green, indicating low importance.
* **self\_attn.q\_proj:** Layers 0-7 are dark blue, indicating high importance. Layers 8-14 transition to lighter shades of blue, indicating decreasing importance. Layers 15-27 transition to light green, indicating low importance.
* **self\_attn.k\_proj:** Layers 0-7 are dark blue, indicating high importance. Layers 8-14 transition to lighter shades of blue, indicating decreasing importance. Layers 15-27 transition to light green, indicating low importance.
* **post\_attention\_layernorm:** All layers (0-27) are light green, indicating low importance.
* **input\_layernorm:** All layers (0-27) are light green, indicating low importance.
* **self\_attn.k\_norm:** All layers (0-27) are light green, indicating low importance.
* **self\_attn.q\_norm:** All layers (0-27) are light green, indicating low importance.
### Key Observations
* The parameters `mlp.down_proj`, `mlp.up_proj`, and `self_attn.o_proj` show high importance for the lower layers (0-14) and decreasing importance for the higher layers (15-27).
* The parameters `mlp.gate_proj`, `self_attn.v_proj`, `self_attn.q_proj`, and `self_attn.k_proj` show high importance for the very lower layers (0-7), decreasing importance for the middle layers (8-14), and low importance for the higher layers (15-27).
* The parameters `post_attention_layernorm`, `input_layernorm`, `self_attn.k_norm`, and `self_attn.q_norm` consistently show low importance across all layers.
### Interpretation
The heatmap suggests that the lower layers (0-14) of the neural network are more critical for the `mlp.down_proj`, `mlp.up_proj`, and `self_attn.o_proj` parameters. The parameters `mlp.gate_proj`, `self_attn.v_proj`, `self_attn.q_proj`, and `self_attn.k_proj` are only important in the very lower layers (0-7). The parameters `post_attention_layernorm`, `input_layernorm`, `self_attn.k_norm`, and `self_attn.q_norm` may not significantly contribute to the network's performance, or their importance is distributed differently across the network architecture. This information can be used to optimize the network architecture, potentially by focusing on the lower layers for specific parameters or by simplifying the network by removing or reducing the influence of the less important parameters.