\n
## Screenshot: Reinforcement Learning Environment
### Overview
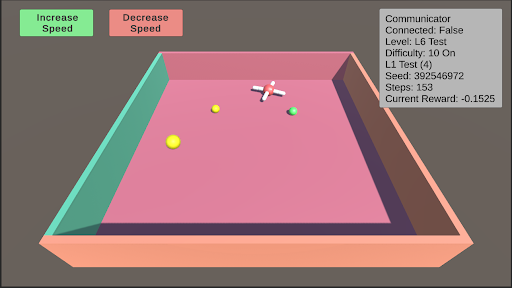
The image depicts a screenshot of a 3D reinforcement learning environment. It appears to be a simulated arena with a central agent (a white, cross-shaped object) and several colored spheres. The environment includes controls for adjusting the agent's speed and a status panel displaying various parameters of the simulation.
### Components/Axes
The screenshot contains the following elements:
* **Arena:** A rectangular, pink-colored arena with raised, teal-colored walls.
* **Agent:** A white, cross-shaped object positioned near the center of the arena.
* **Spheres:** Three spheres of different colors: yellow, orange, and green.
* **Controls:** Two rectangular buttons labeled "Increase Speed" (green) and "Decrease Speed" (orange) located in the top-left corner.
* **Status Panel:** A rectangular panel in the top-right corner displaying simulation parameters.
### Content Details
The status panel displays the following information:
* **Communicator:** Connected: False
* **Level:** L6 Test
* **Difficulty:** 10 On
* **L1 Test:** (4)
* **Seed:** 392546972
* **Steps:** 153
* **Current Reward:** -0.1525
The spheres are positioned as follows (approximate relative to the agent):
* **Yellow Sphere:** Located below the agent.
* **Orange Sphere:** Located to the left of the agent.
* **Green Sphere:** Located to the right of the agent.
### Key Observations
The "Communicator" is disconnected. The simulation is at Level 6 with a difficulty of 10. The simulation has run for 153 steps and currently has a negative reward of -0.1525. The agent is positioned centrally within the arena, with three spheres distributed around it.
### Interpretation
This screenshot represents a snapshot of a reinforcement learning agent interacting with its environment. The negative reward suggests the agent is not yet performing optimally. The disconnected communicator might indicate a lack of external control or data logging. The level and difficulty settings suggest a progressive learning setup. The agent's central position and the distribution of spheres imply a task involving navigation and interaction with these objects, likely to maximize reward. The environment appears to be designed for testing and training an AI agent to learn a specific behavior within a constrained space. The seed value indicates the simulation is reproducible. The number of steps and current reward provide insight into the agent's learning progress.