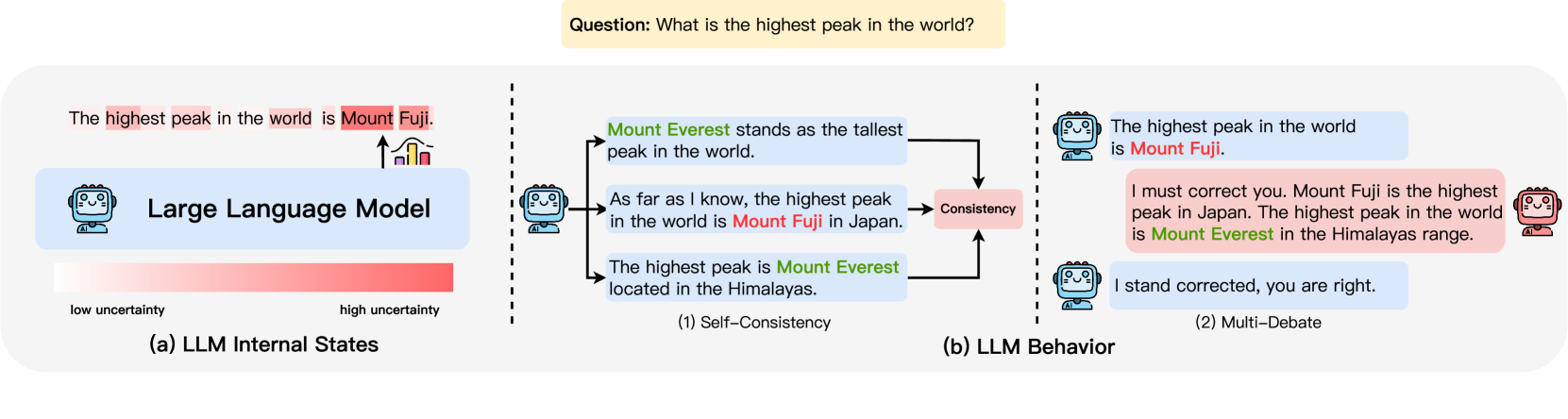
## Diagram: LLM Uncertainty and Correction Mechanisms
### Overview
This image is a conceptual diagram illustrating two key concepts related to the behavior and internal states of Large Language Models (LLMs). It uses a specific example question—"What is the highest peak in the world?"—to demonstrate how an LLM might generate incorrect information (hallucination) and how mechanisms like self-consistency and multi-debate can lead to correction. The diagram is divided into two primary sections: (a) LLM Internal States and (b) LLM Behavior.
### Components/Axes
The diagram is structured into three main vertical panels, separated by dashed lines.
**Top Element:**
* A yellow text box at the top center contains the prompt: `Question: What is the highest peak in the world?`
**Left Panel: (a) LLM Internal States**
* **Central Icon:** A blue robot icon labeled `Large Language Model`.
* **Output Bubble:** A speech bubble from the robot contains the text: `The highest peak in the world is Mount Fuji.` The words `highest peak`, `world`, and `Mount Fuji` are highlighted in red.
* **Uncertainty Bar:** Below the robot is a horizontal gradient bar. The left end is labeled `low uncertainty` (light pink/white), and the right end is labeled `high uncertainty` (solid red). An arrow points from the robot's output bubble down to the `high uncertainty` end of the bar.
* **Caption:** The panel is labeled `(a) LLM Internal States` at the bottom.
**Center & Right Panels: (b) LLM Behavior**
This section is subdivided into two processes.
**(1) Self-Consistency (Center Panel):**
* **Source:** The same blue robot icon from the left panel is shown.
* **Outputs:** Three speech bubbles branch out from the robot:
1. `Mount Everest stands as the tallest peak in the world.` (Text `Mount Everest` is in green).
2. `As far as I know, the highest peak in the world is Mount Fuji in Japan.` (Text `Mount Fuji` is in red).
3. `The highest peak is Mount Everest located in the Himalayas.` (Text `Mount Everest` is in green).
* **Flow:** Arrows from all three bubbles point to a central pink box labeled `Consistency`.
* **Caption:** This subsection is labeled `(1) Self-Consistency` at the bottom.
**(2) Multi-Debate (Right Panel):**
* **Initial Exchange:**
* A blue robot icon states: `The highest peak in the world is Mount Fuji.` (`Mount Fuji` in red).
* A red robot icon (different design) responds: `I must correct you. Mount Fuji is the highest peak in Japan. The highest peak in the world is Mount Everest in the Himalayas range.` (`Mount Everest` in green).
* **Resolution:** A blue robot icon (same as the first) replies: `I stand corrected, you are right.`
* **Caption:** This subsection is labeled `(2) Multi-Debate` at the bottom.
### Detailed Analysis
The diagram presents a narrative flow from error to correction.
1. **Initial Error Generation (Left Panel):** The LLM is depicted as confidently generating a factually incorrect statement ("Mount Fuji is the highest peak"). This output is explicitly linked to a state of `high uncertainty` within the model's internal state, suggesting a disconnect between the model's confidence and its accuracy.
2. **Path to Correction via Self-Consistency (Center Panel):** The same LLM, when prompted multiple times (implied by the three outputs), generates a mix of correct and incorrect answers. Two outputs correctly identify `Mount Everest`, while one repeats the `Mount Fuji` error. The `Consistency` box implies that by comparing these multiple outputs, a majority vote or consistency check could identify the correct answer (`Mount Everest`) as the most consistent response.
3. **Path to Correction via Multi-Debate (Right Panel):** This shows a social correction mechanism. One LLM instance (blue) makes the initial error. A second, distinct LLM instance (red) acts as a critic, providing a detailed correction with geographical context. The first LLM then accepts the correction. This models a debate or peer-review process between AI agents.
### Key Observations
* **Color Coding:** The diagram uses a consistent color scheme to denote correctness: **red** for incorrect information (`Mount Fuji`) and **green** for correct information (`Mount Everest`).
* **Iconography:** Different robot icons are used to distinguish between the primary LLM (blue, friendly face) and the correcting agent in the debate (red, different design).
* **Spatial Flow:** The overall flow is from left to right, moving from the internal state of error generation, through one correction mechanism (self-consistency), to another (multi-debate).
* **Textual Emphasis:** Key factual entities (`Mount Fuji`, `Mount Everest`) and evaluative terms (`highest peak`, `Consistency`) are highlighted within the text bubbles for emphasis.
### Interpretation
This diagram serves as a pedagogical tool to explain two strategies for mitigating factual errors (hallucinations) in Large Language Models.
* **The Core Problem:** It visually establishes that an LLM can produce confident but wrong answers (`high uncertainty` state linked to a wrong output), highlighting the challenge of reliability.
* **Self-Consistency as a Solution:** It proposes that generating multiple responses to the same query and selecting the most frequent or "consistent" answer can filter out one-off errors. The diagram suggests the model's internal uncertainty might manifest as variability in its outputs.
* **Multi-Debate as a Solution:** It illustrates a more interactive approach where multiple AI agents, potentially with different training or prompting, can critique and correct each other. This mimics human collaborative reasoning and fact-checking.
* **Underlying Message:** The diagram argues that while individual LLM outputs may be unreliable, structured processes—either internal (sampling and consistency checking) or external (debate between agents)—can harness the model's capabilities to arrive at more accurate and trustworthy conclusions. It shifts the focus from the infallibility of a single output to the robustness of a *process* involving the LLM.