\n
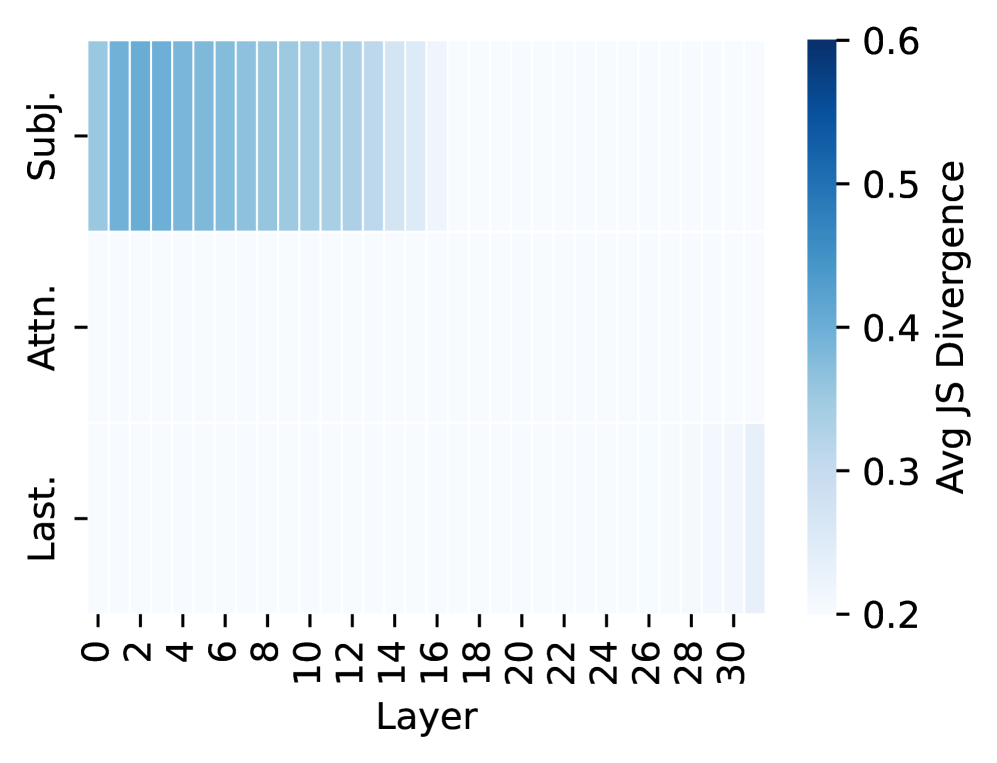
## Heatmap: Average Jensen-Shannon Divergence by Layer and Representation
### Overview
This image presents a heatmap visualizing the average Jensen-Shannon (JS) Divergence across different layers of a model, for three different representations: Subject ('Subj.'), Attention ('Attn.'), and Last Layer ('Last.'). The heatmap uses a blue color gradient to represent divergence values, with darker blues indicating higher divergence.
### Components/Axes
* **X-axis:** Layer, ranging from 0 to 30, with increments of 2.
* **Y-axis:** Representation, with three categories: 'Subj.', 'Attn.', and 'Last.'.
* **Color Scale:** Average JS Divergence, ranging from 0.2 (light blue) to 0.6 (dark blue). The scale is positioned on the right side of the heatmap.
### Detailed Analysis
The heatmap displays JS Divergence values for each combination of layer and representation.
* **Subject ('Subj.') Representation:** The JS Divergence remains relatively constant across layers 0 to 30, hovering around approximately 0.55 ± 0.02. There is a slight decrease in divergence around layer 28, dropping to approximately 0.52.
* **Attention ('Attn.') Representation:** The JS Divergence is consistently lower than for the 'Subj.' representation, generally around 0.40 ± 0.02. There is a slight increase in divergence from layer 0 to layer 6, rising from approximately 0.38 to 0.42. It remains relatively stable until layer 26, where it begins to increase, reaching approximately 0.45 by layer 30.
* **Last Layer ('Last.') Representation:** The JS Divergence starts at approximately 0.25 at layer 0 and increases steadily with increasing layer number. By layer 30, the divergence reaches approximately 0.55. The increase appears roughly linear.
### Key Observations
* The 'Subj.' representation exhibits the highest and most stable JS Divergence across all layers.
* The 'Last.' representation shows the lowest divergence at early layers, but its divergence increases significantly as the layer number increases.
* The 'Attn.' representation has intermediate divergence values, with a slight increase towards the later layers.
* There is a clear trend of increasing divergence in the 'Last.' representation as the layer number increases.
### Interpretation
The heatmap suggests that the 'Subject' representation maintains a consistent level of information throughout the layers, as indicated by the stable JS Divergence. This could imply that the subject information is well-preserved during processing. The 'Last' layer representation, initially having low divergence, becomes more divergent as the layer number increases, suggesting that the information in this representation becomes more distinct or specialized as it passes through the model. The 'Attention' representation shows a moderate level of divergence, with a slight increase in later layers, potentially indicating that the attention mechanism is learning to focus on different aspects of the input as processing progresses. The increasing divergence in the 'Last' layer could be indicative of feature extraction or transformation, where the representation becomes more specific to the task at hand. The differences in divergence values between the representations suggest that each representation captures different aspects of the input data and evolves differently during processing.