\n
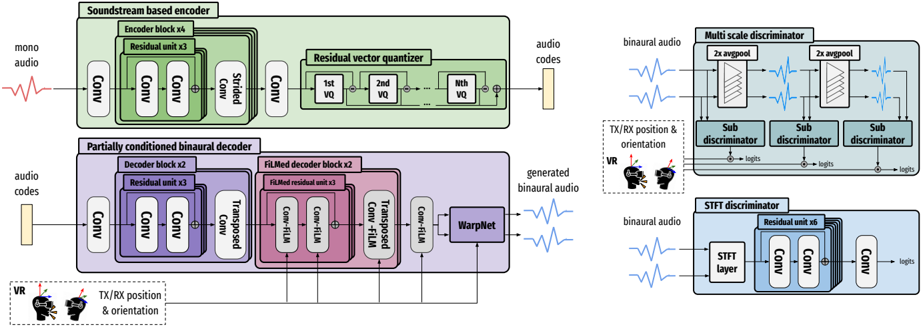
## Diagram: Soundstream-Based Neural Audio Synthesis Pipeline
### Overview
This diagram illustrates a neural audio synthesis pipeline, specifically for generating binaural audio. The pipeline consists of a Soundstream-based encoder, a partially conditioned binaural decoder, and multiple discriminators (Multi-scale, STFT). It takes mono audio as input and outputs generated binaural audio, conditioned on TX/RX position & orientation (represented by a VR headset icon). The diagram details the architecture of each component, including convolutional layers, residual blocks, vector quantization, and transposed convolutions.
### Components/Axes
The diagram is segmented into four main sections:
1. **Soundstream based encoder** (Top-left, green background)
2. **Partially conditioned binaural decoder** (Bottom-left, purple/pink background)
3. **Multi-scale discriminator** (Top-right, light blue background)
4. **STFT discriminator** (Bottom-right, light blue background)
Key elements within these sections include:
* **Input:** Mono audio (represented by a waveform) and audio codes.
* **Output:** Generated binaural audio (represented by a waveform).
* **Conditioning:** TX/RX position & orientation (represented by a VR headset icon).
* **Layers/Blocks:** Conv (Convolutional layers), Residual blocks, Strided Conv, VQ (Vector Quantizer), FiLM (Feature-wise Linear Modulation), WarpNet, Sub-discriminator, STFT layer.
### Detailed Analysis or Content Details
**1. Soundstream based encoder:**
* **Input:** Mono audio.
* **Encoder Block x6:** Contains a series of convolutional layers (Conv) and residual blocks (Residual unit x3).
* **Strided Conv:** A strided convolutional layer.
* **Residual vector quantizer:** Contains three Vector Quantizers (1st VQ, 2nd VQ, Nth VQ).
* **Output:** Audio codes.
**2. Partially conditioned binaural decoder:**
* **Input:** Audio codes and TX/RX position & orientation.
* **Decoder Block x2:** Contains a series of convolutional layers (Conv) and residual blocks (Residual unit x3).
* **FiLMed decoder block x2:** Contains transposed convolutional layers (Transposed Conv) and FiLM layers (Conv-FiLM).
* **WarpNet:** A network for warping features.
* **Output:** Generated binaural audio.
**3. Multi-scale discriminator:**
* **Input:** Binaural audio.
* **2x avgpool:** Two average pooling layers.
* **Sub-discriminator:** Three sub-discriminators, each outputting a "logits" value.
* **Output:** Logits.
**4. STFT discriminator:**
* **Input:** Binaural audio.
* **STFT layer:** Short-Time Fourier Transform layer.
* **Residual unit x6:** Contains a series of convolutional layers (Conv) and residual blocks (Residual unit x6).
* **Output:** Logits.
The diagram shows data flow from left to right. The encoder transforms mono audio into audio codes. The decoder uses these codes, along with positional information, to generate binaural audio. The multi-scale and STFT discriminators evaluate the generated audio, providing feedback (logits) to improve the synthesis process.
### Key Observations
* The pipeline utilizes a combination of convolutional, residual, and transposed convolutional layers, suggesting a deep learning approach.
* The use of vector quantization (VQ) indicates a discrete representation of audio features.
* The inclusion of FiLM layers suggests that the positional information is integrated into the decoding process through feature modulation.
* The presence of two discriminators (multi-scale and STFT) indicates a focus on both high-level perceptual quality and low-level spectral accuracy.
* The VR headset icon clearly indicates the intended application of this pipeline is for virtual reality audio.
### Interpretation
This diagram represents a sophisticated neural audio synthesis pipeline designed to generate realistic binaural audio for virtual reality applications. The encoder compresses the input mono audio into a latent representation (audio codes), while the decoder reconstructs the audio as binaural output, conditioned on the user's head position and orientation. The discriminators act as adversarial networks, pushing the generator (decoder) to produce audio that is indistinguishable from real binaural recordings. The architecture suggests a focus on both perceptual realism (through the multi-scale discriminator) and spectral accuracy (through the STFT discriminator). The use of FiLM layers allows for dynamic adaptation of the audio based on the user's position, creating a more immersive and spatially accurate audio experience. The pipeline leverages recent advances in neural audio synthesis, including vector quantization and feature-wise linear modulation, to achieve high-quality binaural audio generation. The diagram does not provide specific numerical values or performance metrics, but it clearly outlines the key components and data flow of the system.