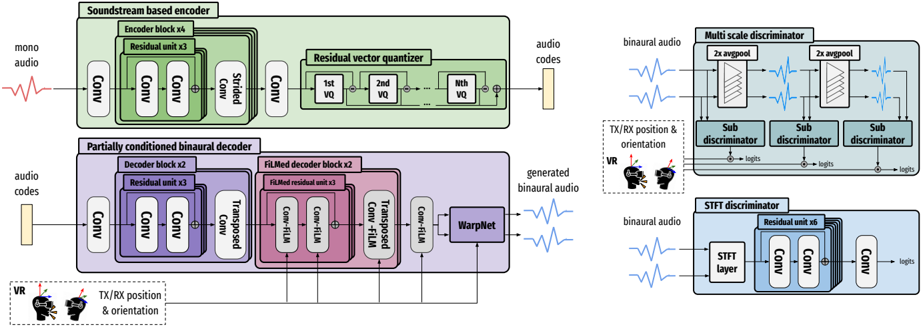
## Neural Architecture Diagram: Audio Processing System
### Overview
The diagram illustrates a complex neural network architecture for binaural audio generation, featuring three main components: a soundstream-based encoder, a partially conditioned binaural decoder, and two discriminator systems (multi-scale and STFT). The architecture includes spatial audio processing elements (VR/TX/RX position & orientation) and demonstrates a GAN-like framework for audio synthesis and evaluation.
### Components/Axes
1. **Left Section (Encoder/Decoder Flow)**
- **Input**: Mono audio waveform (red sine wave)
- **Encoder Blocks**:
- Green blocks: "Soundstream based encoder" with residual units (x3), strided convolution, and residual vector quantizer (VQ)
- Output: Audio codes (yellow block)
- **Decoder Blocks**:
- Purple blocks: "Partially conditioned binaural decoder" with FiLM decoder units (x3), transposed convolutions, and WarpNet
- Inputs: Audio codes + VR/TX/RX position & orientation
- Output: Generated binaural audio (blue waveform)
2. **Right Section (Discriminators)**
- **Multi-scale Discriminator**:
- Blue blocks with 2x avgpool layers
- Sub-discriminators (3 instances)
- Input: Binaural audio + VR/TX/RX position & orientation
- **STFT Discriminator**:
- Blue blocks with residual units (x6) and convolutional layers
- Input: Binaural audio
- Output: Logits
3. **Spatial Elements**:
- VR headset icon with directional arrows
- TX/RX position & orientation indicators
### Detailed Analysis
- **Encoder Flow**:
- Mono audio → 4 Conv layers → 3 Residual units → Strided Conv → 4 Conv layers → Residual Vector Quantizer (VQ1-VQn) → Audio codes
- Color coding: Green for encoder components
- **Decoder Flow**:
- Audio codes + VR/TX/RX → 2 Conv layers → 3 Residual units → 2 Conv layers → FiLM decoder blocks (x3) → Transposed Conv → WarpNet → Binaural audio
- Color coding: Purple for decoder components
- **Discriminator Structure**:
- Multi-scale: 2x avgpool → 3 sub-discriminators (each with 2x avgpool)
- STFT: Residual unit (x6) → 3 Conv layers → Logits
- Color coding: Blue for discriminator components
### Key Observations
1. **Hierarchical Processing**:
- Encoder uses residual units and VQ for feature extraction
- Decoder employs FiLM conditioning for spatial audio generation
- Discriminators use multi-scale and spectral (STFT) analysis
2. **Spatial Conditioning**:
- VR/TX/RX position/orientation inputs appear in both encoder and decoder paths
- Critical for binaural audio spatialization
3. **GAN Architecture**:
- Encoder-decoder generates audio
- Discriminators evaluate quality through:
- Multi-scale temporal analysis
- Spectral/temporal STFT analysis
4. **Color Coding**:
- Green: Encoder components
- Purple: Decoder components
- Blue: Discriminator components
### Interpretation
This architecture represents a state-of-the-art approach for spatial audio generation using VQ-VAE-GAN principles. The encoder compresses audio into discrete codes while preserving spatial information through residual units. The decoder reconstructs binaural audio by conditioning on VR/TX/RX data through FiLM mechanisms, enabling precise spatial audio reproduction. The dual discriminator system ensures high-quality generation by evaluating both temporal (multi-scale) and spectral (STFT) characteristics. The architecture's strength lies in its ability to maintain spatial coherence while generating high-fidelity binaural audio, making it suitable for VR/AR applications and immersive audio experiences.