## Diagram: Online Decision Algorithm
### Overview
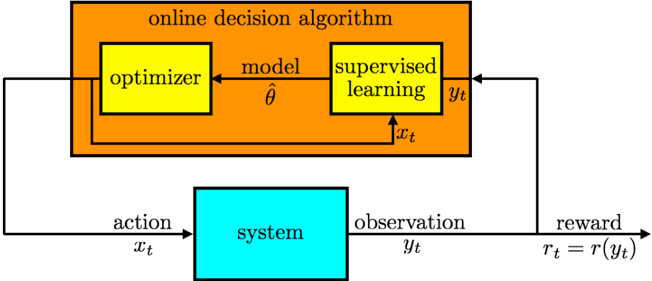
The image is a block diagram illustrating an online decision algorithm interacting with a system. The algorithm consists of an optimizer and a supervised learning component, which exchange information to make decisions that affect the system. The system, in turn, provides observations back to the algorithm, closing the loop.
### Components/Axes
* **Title:** "online decision algorithm" (located at the top, within the orange box)
* **Components:**
* "optimizer" (yellow box, top-left within the orange box)
* "supervised learning" (yellow box, top-right within the orange box)
* "system" (cyan box, bottom center)
* **Variables:**
* "model" (above the arrow from optimizer to supervised learning), represented by the symbol "θ" (theta) with a hat.
* "action" (above the arrow from the online decision algorithm to the system), represented by "x_t".
* "observation" (above the arrow from the system to the online decision algorithm), represented by "y_t".
* "reward" (above the arrow from the system back to the online decision algorithm), represented by "r_t = r(y_t)".
### Detailed Analysis
The diagram shows the flow of information and actions between the online decision algorithm and the system.
1. **Online Decision Algorithm:** The algorithm, enclosed in an orange box, contains two main components:
* **Optimizer:** The optimizer (yellow box) generates a "model" (θ with a hat) that is sent to the supervised learning component.
* **Supervised Learning:** The supervised learning component (yellow box) receives the model and the action "x_t" from the system. It outputs "y_t".
2. **System:** The system (cyan box) receives an "action" (x_t) from the online decision algorithm. Based on this action, the system produces an "observation" (y_t) and a "reward" (r_t = r(y_t)).
3. **Feedback Loop:** The "observation" (y_t) is fed back to the supervised learning component, and the "reward" (r_t) is fed back to the optimizer, closing the feedback loop.
### Key Observations
* The diagram illustrates a closed-loop control system where the online decision algorithm learns and adapts based on the system's response to its actions.
* The optimizer and supervised learning components work together to make decisions.
* The reward signal is a function of the observation, indicating that the algorithm's performance is evaluated based on the system's state.
### Interpretation
The diagram represents a reinforcement learning or adaptive control system. The online decision algorithm learns to control the system by observing its behavior and adjusting its actions to maximize the reward. The optimizer likely updates the model based on the reward signal, while the supervised learning component uses the model and observations to predict the system's future state or to select the best action. The feedback loop allows the algorithm to continuously improve its performance over time. The diagram highlights the key components and interactions involved in this type of system.