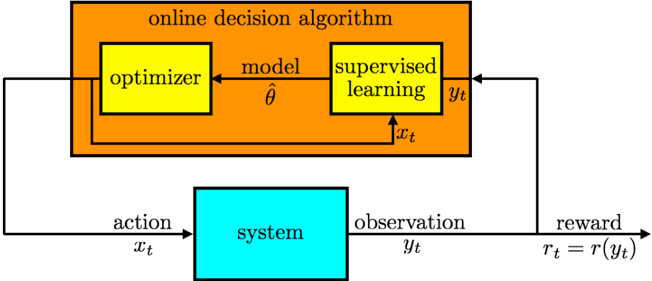
## Diagram: Online Decision Algorithm Feedback Loop
### Overview
The image is a technical block diagram illustrating the architecture of an **online decision algorithm** and its interaction with an external **system**. It depicts a closed-loop feedback process where the algorithm generates actions, receives observations and rewards from the system, and uses this data to update its internal model. The diagram uses colored blocks and labeled arrows to represent components and data flows.
### Components/Axes
The diagram is composed of two primary blocks and connecting data flows:
1. **Main Block (Orange):** Labeled **"online decision algorithm"**. This block contains two sub-components:
* **Optimizer (Yellow Box, Left):** Labeled **"optimizer"**.
* **Supervised Learning (Yellow Box, Right):** Labeled **"supervised learning"**.
2. **External System (Cyan Box):** Labeled **"system"**. Positioned below the main algorithm block.
3. **Data Flows (Arrows with Labels):**
* **Action Flow:** An arrow from the **"optimizer"** to the **"system"**, labeled **"action"** with the variable **`x_t`**.
* **Observation Flow:** An arrow from the **"system"** to the **"supervised learning"** block, labeled **"observation"** with the variable **`y_t`**.
* **Reward Flow:** An arrow originating from the system's output path, labeled **"reward"** with the equation **`r_t = r(y_t)`**, pointing to the **"supervised learning"** block.
* **Internal Model Flow:** An arrow from the **"supervised learning"** block to the **"optimizer"**, labeled **"model"** with the parameter symbol **`θ̂`** (theta-hat).
* **Internal Data Flow:** An arrow from the **"optimizer"** to the **"supervised learning"** block, labeled with the variable **`x_t`**.
### Detailed Analysis
The diagram explicitly defines the following components and their relationships:
* **Spatial Layout:** The "online decision algorithm" block is positioned at the top. The "system" block is centered below it. The "optimizer" is on the left side within the algorithm block, and "supervised learning" is on the right.
* **Component Labels & Variables:**
* **Optimizer:** Takes input (implied from the model `θ̂`) and produces an action `x_t`.
* **Supervised Learning:** Receives the observation `y_t` and reward `r_t` from the system, and the action `x_t` from the optimizer. It outputs an updated model parameter `θ̂` to the optimizer.
* **System:** Receives action `x_t` and produces observation `y_t`. The reward `r_t` is a function of this observation, `r(y_t)`.
* **Flow Direction & Logic:** The arrows establish a clear cyclical process:
1. The optimizer, using model `θ̂`, decides on action `x_t`.
2. Action `x_t` is applied to the system.
3. The system responds with observation `y_t`.
4. The reward `r_t` is calculated as a function of `y_t`.
5. Both `y_t` and `r_t` are fed into the supervised learning module, along with the action `x_t` that caused them.
6. The supervised learning module updates the model parameter `θ̂`.
7. The new `θ̂` is sent to the optimizer, completing the loop for the next time step (`t`).
### Key Observations
* **Closed-Loop System:** The diagram represents a classic feedback control or reinforcement learning loop. The algorithm's decisions directly influence the system, and the system's outputs directly influence the algorithm's future decisions.
* **Role of Supervised Learning:** The supervised learning component acts as the **model updater**. It uses the triplet of data `(x_t, y_t, r_t)`—the action taken, the resulting observation, and the resulting reward—to refine the model parameter `θ̂`. This suggests the algorithm learns from its own experience in an online fashion.
* **Reward Definition:** The reward `r_t` is explicitly defined as a function `r(y_t)` of the observation `y_t`. This means the reward signal is derived from the system's state or output, not provided externally as a separate input.
* **Notation:** The subscript `t` denotes a discrete time step, indicating this is a sequential, iterative process. The hat symbol on `θ̂` typically denotes an *estimate* of a parameter.
### Interpretation
This diagram illustrates the core architecture of an **adaptive, online learning system**. It is not a static model but a dynamic process where the decision-making policy (encapsulated in the model `θ̂`) is continuously updated based on real-time interaction with an environment (the "system").
The key insight is the separation of concerns: the **optimizer** is responsible for *acting* (policy execution), while the **supervised learning** module is responsible for *learning* (policy improvement). The system provides the ground truth through its responses (`y_t`) and the performance metric (`r_t`).
This structure is fundamental to fields like **reinforcement learning**, **adaptive control**, and **online optimization**. The "online" aspect is critical—the algorithm must learn and improve while simultaneously performing its task, without the luxury of a large, pre-collected dataset. The efficiency and stability of the "supervised learning" update rule for `θ̂` would be the primary determinant of the system's overall performance.