\n
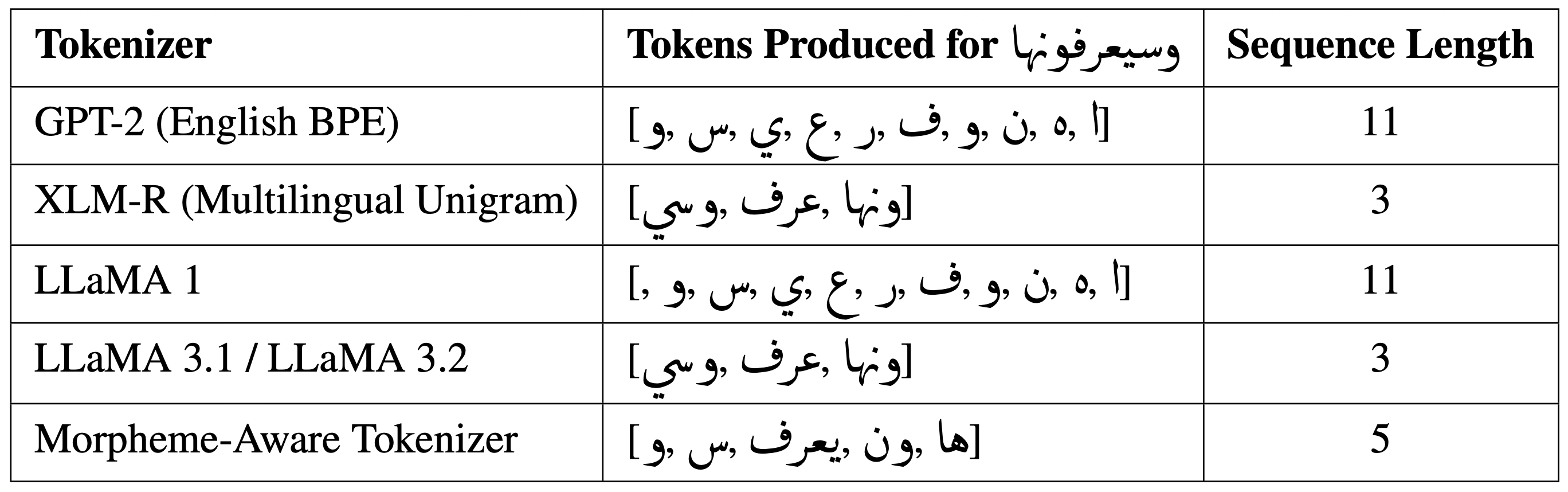
## Data Table: Tokenization Results for Different Tokenizers
### Overview
This image presents a data table comparing the tokenization results of five different tokenizers when applied to a specific Arabic phrase: "وسيعرفونها". The table shows the tokens produced by each tokenizer and the resulting sequence length.
### Components/Axes
The table has three columns:
1. **Tokenizer:** Lists the name of the tokenizer used.
2. **Tokens Produced for وسيعرفونها:** Displays the tokens generated by each tokenizer for the Arabic phrase. The Arabic phrase is "وسيعرفونها" (wasiya'rifunaha).
3. **Sequence Length:** Indicates the number of tokens produced by each tokenizer.
The tokenizers listed are:
* GPT-2 (English BPE)
* XLM-R (Multilingual Unigram)
* LLaMA 1
* LLaMA 3.1 / LLaMA 3.2
* Morpheme-Aware Tokenizer
### Content Details
Here's a reconstruction of the table's content:
| Tokenizer | Tokens Produced for وسيعرفونها | Sequence Length |
|---|---|---|
| GPT-2 (English BPE) | [!, ٠, ة, ن, و, ف, ر, ع, ي, س, و,] | 11 |
| XLM-R (Multilingual Unigram) | [اونها, يعرف, وسى] | 3 |
| LLaMA 1 | [!, ٠, ة, ن, و, ف, ر, ع, ي, س, و,] | 11 |
| LLaMA 3.1 / LLaMA 3.2 | [اونها, يعرف, وسى] | 3 |
| Morpheme-Aware Tokenizer | [ها, وون, يعرف, س, و] | 5 |
The Arabic phrase "وسيعرفونها" (wasiya'rifunaha) translates to "And they will know".
### Key Observations
* GPT-2 and LLaMA 1 produce the same set of tokens and have the longest sequence length (11). These tokens include punctuation and seemingly arbitrary characters.
* XLM-R and LLaMA 3.1/3.2 produce the same tokens and have the shortest sequence length (3). These tokens appear to be more meaningful segments of the Arabic phrase.
* The Morpheme-Aware Tokenizer produces 5 tokens, representing a middle ground in terms of sequence length.
### Interpretation
The table demonstrates how different tokenizers handle Arabic text differently. GPT-2 and LLaMA 1, being trained primarily on English, appear to break down the Arabic phrase into a large number of subword units, potentially including characters that are not semantically meaningful in the context of Arabic. XLM-R and LLaMA 3.1/3.2, designed for multilingual processing, are able to segment the phrase into more coherent tokens. The Morpheme-Aware Tokenizer attempts to identify morphemes (meaningful units of language), resulting in a sequence length between the two extremes.
The differing sequence lengths have implications for model efficiency and performance. Shorter sequences require less computational resources, but may lose some of the nuance of the original text. Longer sequences capture more detail but can increase computational cost and potentially introduce noise. The choice of tokenizer depends on the specific application and the trade-off between these factors. The presence of punctuation and seemingly random characters in the GPT-2 and LLaMA 1 tokenization suggests that these models may not be optimally suited for processing Arabic text without further fine-tuning or adaptation.