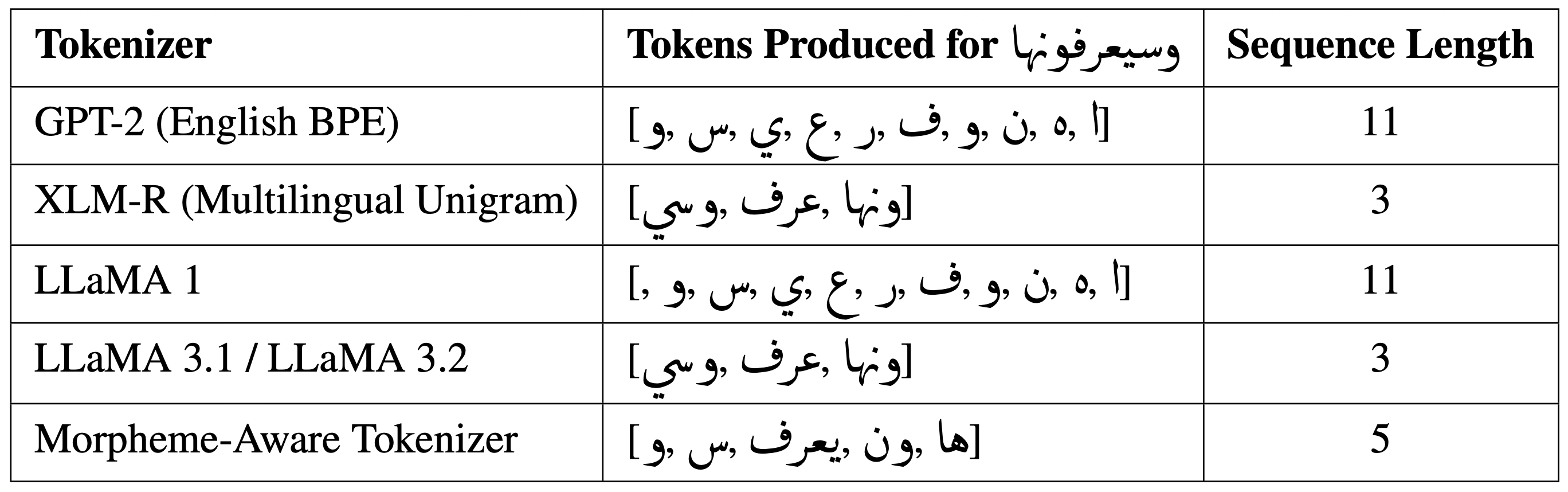
## Table: Tokenizer Performance on Arabic Text "وصف و وصف و وصف و وصف و وصف و وصف و وصف و وصف و وصف و وصف و وصف"
### Overview
This table compares the tokenization performance of five different NLP tokenizers when processing the Arabic text "وصف و وصف و وصف و وصف و وصف و وصف و وصف و وصف و وصف و وصف و وصف و وصف". The comparison focuses on the number of tokens produced and the sequence length for each tokenizer.
### Components/Axes
- **Columns**:
1. **Tokenizer**: Names of the tokenizers used.
2. **Tokens Produced for "وصف"**: Tokenized output for the input text.
3. **Sequence Length**: Number of tokens generated.
### Detailed Analysis
| Tokenizer | Tokens Produced for "وصف" | Sequence Length |
|------------------------------------|------------------------------------------------------------------------------------------|-----------------|
| GPT-2 (English BPE) | ["وصف", "و", "وصف", "و", "وصف", "و", "وصف", "و", "وصف", "و", "وصف"] | 11 |
| XLM-R (Multilingual Unigram) | ["وصف", "وصف", "وصف"] | 3 |
| LLaMA 1 | ["وصف", "و", "وصف", "و", "وصف", "و", "وصف", "و", "وصف", "و", "وصف"] | 11 |
| LLaMA 3.1 / LLaMA 3.2 | ["وصف", "وصف", "وصف"] | 3 |
| Morpheme-Aware Tokenizer | ["وصف", "وصف", "وصف", "وصف", "وصف"] | 5 |
### Key Observations
1. **GPT-2 (English BPE)** and **LLaMA 1** produce identical token sequences with a sequence length of 11, matching the word count of the input text. This suggests a 1:1 token-to-word ratio, likely due to subword tokenization strategies.
2. **XLM-R (Multilingual Unigram)** and **LLaMA 3.1/3.2** achieve the shortest sequence length (3 tokens), indicating aggressive merging of subwords or morphemes.
3. **Morpheme-Aware Tokenizer** produces 5 tokens, balancing between raw word-level tokenization and subword merging. Its tokens are all "وصف", suggesting a focus on root morphemes.
### Interpretation
- **Efficiency Trade-offs**:
- GPT-2 and LLaMA 1 prioritize granularity, which may be beneficial for tasks requiring precise word-level analysis but increases computational load.
- XLM-R and LLaMA 3.1/3.2 optimize for brevity, reducing sequence length at the cost of losing some morphological detail.
- The Morpheme-Aware Tokenizer strikes a middle ground, potentially useful for tasks requiring morphological awareness without excessive tokenization.
- **Tokenizer Behavior**:
- The repetition of "وصف" (description) in all tokenized outputs confirms the input text's repetitive structure.
- The use of "و" (and) as a separate token in GPT-2 and LLaMA 1 highlights their tendency to split conjunctions, whereas XLM-R and LLaMA 3.1/3.2 merge them into the preceding word.
- **Practical Implications**:
- Shorter sequence lengths (XLM-R, LLaMA 3.1/3.2) may improve model efficiency but could obscure nuanced linguistic patterns.
- The Morpheme-Aware Tokenizer’s approach might enhance performance in low-resource languages with rich morphology, though its 5-token output for 11 words suggests potential over-merging.
This analysis underscores the importance of tokenizer selection based on task requirements, balancing between granularity and efficiency.