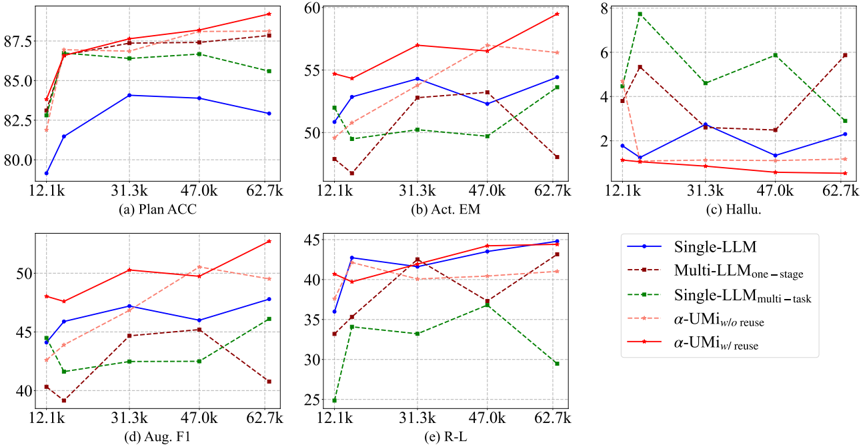
## Line Charts: Performance Comparison of Different LLM Configurations
### Overview
The image presents a series of five line charts comparing the performance of different Large Language Model (LLM) configurations across various metrics. The x-axis represents the data size (in thousands), and the y-axis represents the performance score for each metric. The charts compare "Single-LLM", "Multi-LLMone-stage", "Single-LLMmulti-task", "α-UMIw/o reuse", and "α-UMIw/ reuse".
### Components/Axes
* **X-axis (all charts):** Data size in thousands, labeled with values 12.1k, 31.3k, 47.0k, and 62.7k.
* **Y-axis (Plan ACC):** Performance score ranging from 80.0 to 87.5.
* **Y-axis (Act. EM):** Performance score ranging from 50 to 60.
* **Y-axis (Hallu.):** Performance score ranging from 0 to 8.
* **Y-axis (Aug. F1):** Performance score ranging from 40 to 50.
* **Y-axis (R-L):** Performance score ranging from 25 to 45.
* **Chart Titles:** (a) Plan ACC, (b) Act. EM, (c) Hallu., (d) Aug. F1, (e) R-L.
* **Legend (bottom-right):**
* Blue line with circle markers: Single-LLM
* Dark red dashed line with square markers: Multi-LLMone-stage
* Green dashed line with plus markers: Single-LLMmulti-task
* Light red dashed line with no markers: α-UMIw/o reuse
* Red line with triangle markers: α-UMIw/ reuse
### Detailed Analysis
#### (a) Plan ACC (Planning Accuracy)
* **Single-LLM (Blue):** Starts at approximately 79 at 12.1k, increases to ~84 at 31.3k, then remains relatively stable around 84 until 62.7k.
* **Multi-LLMone-stage (Dark Red):** Starts at ~83 at 12.1k, increases to ~87 at 31.3k, then decreases slightly to ~87 at 62.7k.
* **Single-LLMmulti-task (Green):** Starts at ~83 at 12.1k, increases to ~86 at 31.3k, then remains relatively stable around 86 until 62.7k.
* **α-UMIw/o reuse (Light Red):** Starts at ~83 at 12.1k, increases to ~87 at 31.3k, then remains relatively stable around 87 until 62.7k.
* **α-UMIw/ reuse (Red):** Starts at ~84 at 12.1k, increases to ~87 at 31.3k, then increases to ~88 at 62.7k.
#### (b) Act. EM (Action Exact Match)
* **Single-LLM (Blue):** Starts at ~51 at 12.1k, increases to ~54 at 31.3k, then decreases to ~52 at 47.0k, and increases to ~54 at 62.7k.
* **Multi-LLMone-stage (Dark Red):** Starts at ~47 at 12.1k, increases to ~52 at 31.3k, then decreases to ~52 at 47.0k, and decreases to ~48 at 62.7k.
* **Single-LLMmulti-task (Green):** Starts at ~50 at 12.1k, increases to ~50 at 31.3k, then remains relatively stable around 50 until 62.7k.
* **α-UMIw/o reuse (Light Red):** Starts at ~50 at 12.1k, increases to ~57 at 31.3k, then decreases to ~57 at 47.0k, and decreases to ~57 at 62.7k.
* **α-UMIw/ reuse (Red):** Starts at ~54 at 12.1k, increases to ~58 at 31.3k, then increases to ~58 at 47.0k, and increases to ~59 at 62.7k.
#### (c) Hallu. (Hallucination)
* **Single-LLM (Blue):** Starts at ~2 at 12.1k, increases to ~3 at 31.3k, then decreases to ~1 at 47.0k, and increases to ~2 at 62.7k.
* **Multi-LLMone-stage (Dark Red):** Starts at ~5 at 12.1k, decreases to ~1 at 31.3k, then increases to ~2 at 47.0k, and increases to ~6 at 62.7k.
* **Single-LLMmulti-task (Green):** Starts at ~4 at 12.1k, increases to ~8 at 31.3k, then decreases to ~5 at 47.0k, and decreases to ~3 at 62.7k.
* **α-UMIw/o reuse (Light Red):** Starts at ~4 at 12.1k, decreases to ~1 at 31.3k, then remains relatively stable around 1 until 62.7k.
* **α-UMIw/ reuse (Red):** Starts at ~1 at 12.1k, increases to ~1 at 31.3k, then remains relatively stable around 1 until 62.7k.
#### (d) Aug. F1 (Augmented F1 Score)
* **Single-LLM (Blue):** Starts at ~36 at 12.1k, increases to ~46 at 31.3k, then remains relatively stable around 46 until 62.7k.
* **Multi-LLMone-stage (Dark Red):** Starts at ~40 at 12.1k, increases to ~42 at 31.3k, then remains relatively stable around 42 until 62.7k.
* **Single-LLMmulti-task (Green):** Starts at ~44 at 12.1k, decreases to ~42 at 31.3k, then remains relatively stable around 42 until 62.7k.
* **α-UMIw/o reuse (Light Red):** Starts at ~43 at 12.1k, increases to ~43 at 31.3k, then remains relatively stable around 43 until 62.7k.
* **α-UMIw/ reuse (Red):** Starts at ~47 at 12.1k, increases to ~51 at 31.3k, then remains relatively stable around 51 until 62.7k.
#### (e) R-L (Reward Learning)
* **Single-LLM (Blue):** Starts at ~36 at 12.1k, increases to ~43 at 31.3k, then increases to ~44 at 47.0k, and increases to ~45 at 62.7k.
* **Multi-LLMone-stage (Dark Red):** Starts at ~40 at 12.1k, increases to ~42 at 31.3k, then increases to ~42 at 47.0k, and increases to ~44 at 62.7k.
* **Single-LLMmulti-task (Green):** Starts at ~25 at 12.1k, increases to ~33 at 31.3k, then increases to ~37 at 47.0k, and decreases to ~30 at 62.7k.
* **α-UMIw/o reuse (Light Red):** Starts at ~33 at 12.1k, increases to ~42 at 31.3k, then increases to ~42 at 47.0k, and increases to ~43 at 62.7k.
* **α-UMIw/ reuse (Red):** Starts at ~40 at 12.1k, increases to ~43 at 31.3k, then increases to ~43 at 47.0k, and increases to ~45 at 62.7k.
### Key Observations
* **α-UMIw/ reuse (Red):** Generally performs well across all metrics, often achieving the highest scores, especially as the data size increases.
* **Single-LLMmulti-task (Green):** Shows variable performance, sometimes performing well (e.g., Plan ACC) and sometimes underperforming (e.g., R-L).
* **Hallucination (c):** The α-UMIw/ reuse (Red) consistently shows the lowest hallucination rates.
### Interpretation
The charts provide a comparative analysis of different LLM configurations, highlighting the impact of various architectural choices and training strategies on performance across different metrics. The "α-UMIw/ reuse" configuration appears to be a strong performer, particularly in terms of planning accuracy, action exact match, and minimizing hallucination. The performance variations across metrics suggest that different configurations are better suited for specific tasks or evaluation criteria. The increase in data size generally leads to improved performance for most configurations, indicating the importance of data scale in LLM training. The "Hallu." chart is particularly important, as it indicates the model's tendency to generate nonsensical or factually incorrect information. Lower scores on this metric are desirable.