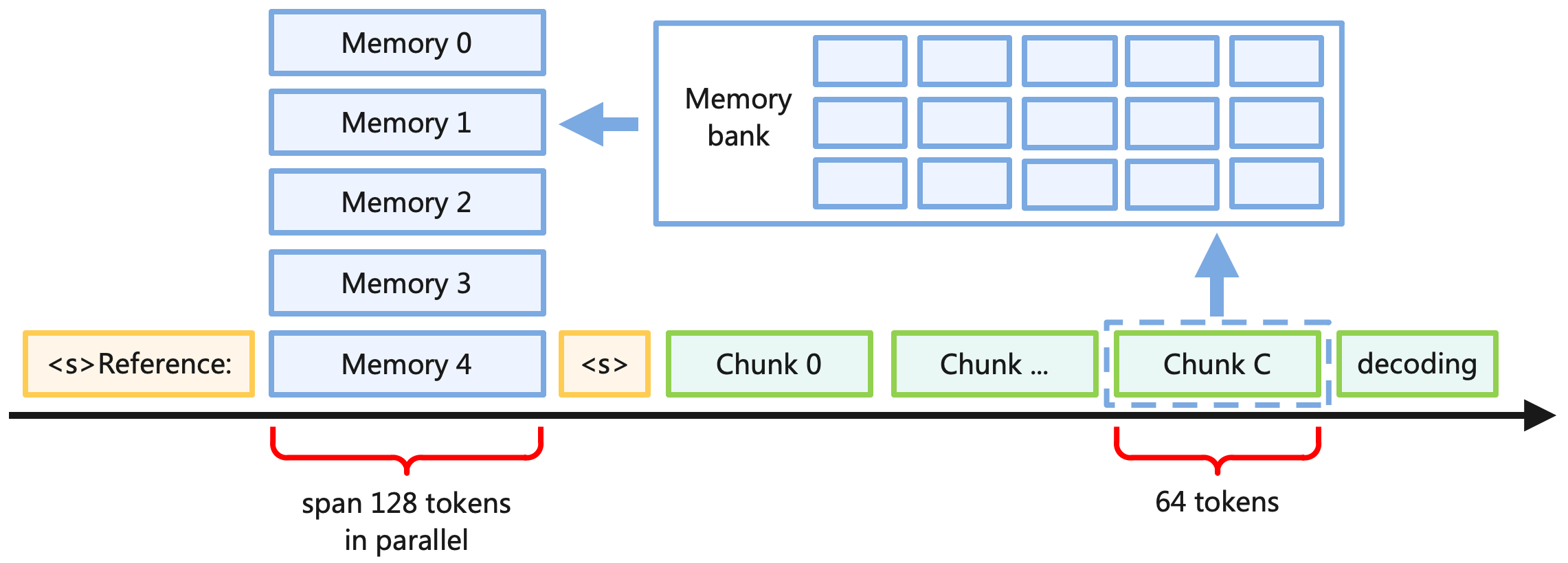
## Diagram: Memory Bank and Token Chunking Processing Flow
### Overview
This image is a technical system architecture diagram illustrating a data processing pipeline, likely related to Natural Language Processing (NLP) or Large Language Models (LLMs). It depicts a chronological sequence of token processing along a bottom timeline, where data is segmented into chunks, stored in a central memory bank, and retrieved into a parallel memory stack to assist in decoding.
### Components and Flow
The diagram consists of several distinct visual elements, color-coded to represent different functions:
* **Timeline:** A long, solid black arrow running horizontally across the bottom from left to right, indicating the progression of time or sequence steps.
* **Special Tokens (Light Orange/Yellow):** Rectangular boxes representing sequence markers or prompts.
* **Memory Stack (Light Blue):** A vertical arrangement of rectangular boxes representing active or retrieved memory states.
* **Processing Chunks (Light Green):** A horizontal sequence of rectangular boxes representing segments of data being processed over time.
* **Storage (Light Blue Outline):** A large container holding a grid of smaller, empty boxes, representing a storage repository.
* **Annotations (Red):** Curly brackets with accompanying black text used to denote token counts and processing spans.
* **Data Flow (Solid Light Blue Arrows):** Arrows indicating the movement of data between the sequence timeline and the storage components.
### Content Details
**1. The Sequence Timeline (Bottom, Left to Right)**
The elements resting directly on or immediately above the black timeline arrow are as follows:
* **Initial Token:** A light orange box containing the text `<s>Reference:`.
* **Active Memory Base:** A light blue box containing the text `Memory 4`.
* *Annotation:* Below `Memory 4`, a red curly bracket spans the width of the box. Below the bracket is the text: `span 128 tokens` (top line) and `in parallel` (bottom line).
* **Separator Token:** A light orange box containing the text `<s>`.
* **Chunk Sequence:** A series of light green boxes:
* `Chunk 0`
* `Chunk ...`
* `Chunk C`
* *Annotation:* `Chunk C` is enclosed in a dashed light blue border. Below `Chunk C`, a red curly bracket spans its width. Below the bracket is the text: `64 tokens`.
* **Final Stage:** A light green box containing the text `decoding`.
**2. The Parallel Memory Stack (Middle Left)**
Rising vertically above the `Memory 4` box (which sits on the timeline) is a stack of identical light blue boxes. From top to bottom, they are labeled:
* `Memory 0`
* `Memory 1`
* `Memory 2`
* `Memory 3`
* (`Memory 4` is at the bottom of this stack).
**3. The Memory Bank (Top Right)**
Positioned above the "Chunk" sequence is a large rectangular box with a light blue outline.
* *Label:* The text `Memory bank` is located on the left interior side of this large box.
* *Grid:* To the right of the label, inside the large box, is a grid of 15 smaller, empty light blue rectangles. They are arranged in 3 horizontal rows and 5 vertical columns.
**4. Data Flow Indicators**
* **Write/Store Flow:** A solid light blue arrow points vertically **upward**. It originates from the top of the dashed border surrounding `Chunk C` and points directly into the bottom of the `Memory bank` container.
* **Read/Retrieve Flow:** A solid light blue arrow points horizontally to the **left**. It originates from the left edge of the `Memory bank` container and points toward the vertical stack of Memory boxes (specifically aiming between `Memory 1` and `Memory 2`, though it implies flow to the entire stack).
### Key Observations
* **Token Quantities:** There is a specific mathematical relationship implied. A single chunk (`Chunk C`) consists of `64 tokens`. The active memory span (`Memory 4`) handles `128 tokens in parallel`. This suggests that the active memory span holds exactly two chunks worth of data (64 x 2 = 128).
* **Parallelism:** The vertical stack of `Memory 0` through `Memory 4` indicates that multiple memory states are held or processed simultaneously, contrasting with the sequential, one-by-one processing of the chunks (`Chunk 0` to `Chunk C`).
* **Nomenclature:** The use of `<s>` is a standard convention in NLP representing a "Start of Sequence" token.
### Interpretation
This diagram illustrates a memory-augmented architecture designed to handle long-context sequences in machine learning models (likely Transformers).
Standard models struggle with infinite context due to memory constraints. This diagram demonstrates a solution:
1. **Chunking:** As the model reads a long input, it breaks the sequence down into manageable blocks (`Chunk 0`, `Chunk ...`, `Chunk C`), with a defined size of 64 tokens per chunk.
2. **External Storage:** Instead of keeping all past tokens in active computational memory, the representations of these processed chunks are pushed (indicated by the upward arrow) into an external or secondary `Memory bank`. The grid inside the bank represents slots where past chunk states (likely Key-Value pairs) are stored.
3. **Retrieval and Parallel Processing:** When the model reaches the `decoding` phase and needs historical context, it does not recalculate the past. Instead, it retrieves relevant historical states from the `Memory bank` (indicated by the leftward arrow) and loads them into a parallel memory buffer (`Memory 0` through `Memory 4`).
4. **Context Window:** The active processing window handles 128 tokens in parallel. Because a chunk is 64 tokens, the system is likely loading multiple past chunks simultaneously into the `Memory 0-4` stack to provide rich, extended context for the current decoding step without overwhelming the primary sequence processor.
In summary, this is a visual representation of a continuous batching or memory-caching mechanism designed to extend the effective context window of a language model by offloading older tokens to a bank and retrieving them in parallel blocks when needed.