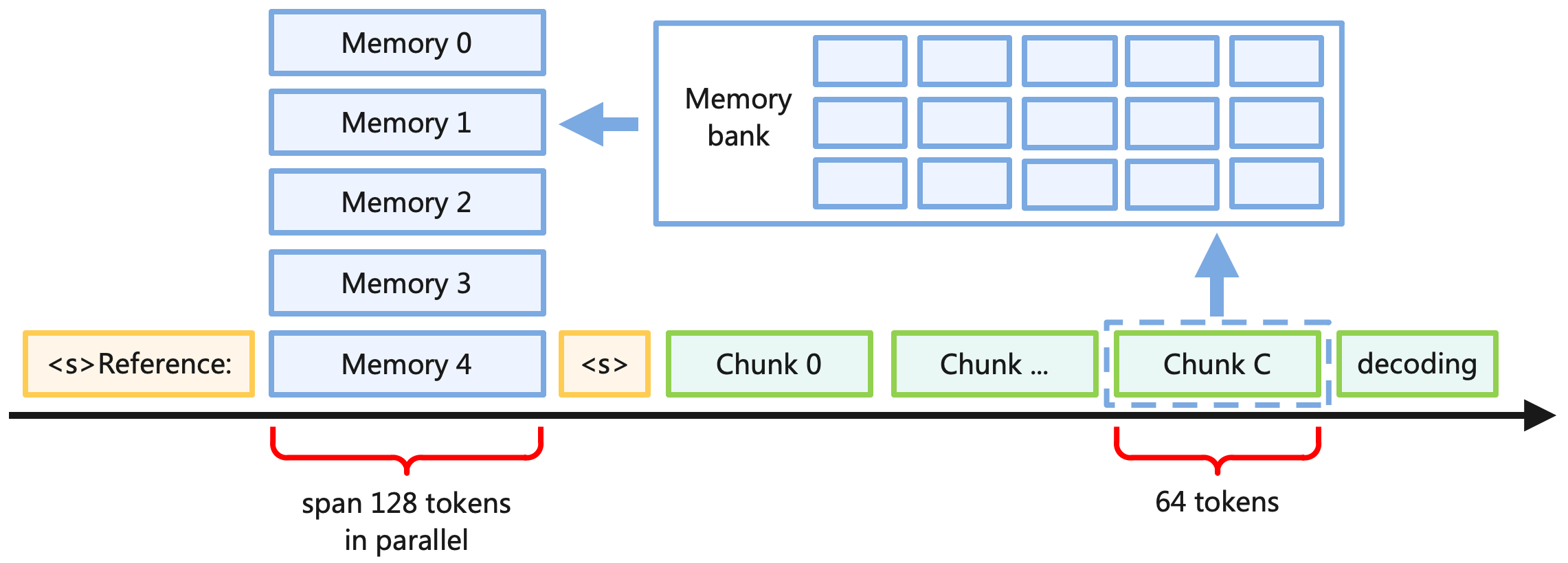
## Diagram: Memory Bank and Chunk Processing Pipeline
### Overview
The diagram illustrates a memory management and data processing pipeline. It shows a sequence of memory blocks (Memory 0–4) feeding into a memory bank, followed by chunked data processing and decoding. Key elements include parallel token spans (128 tokens) and sequential decoding (64 tokens).
### Components/Axes
- **Memory Blocks**: Labeled "Memory 0" to "Memory 4" (vertical stack on the left).
- **Memory Bank**: A 3x4 grid of cells (12 total) connected to Memory 4 via an arrow.
- **Chunks**: Labeled "Chunk 0," "Chunk ...," and "Chunk C" (horizontal sequence after the memory bank).
- **Decoding**: Final stage labeled "decoding" (rightmost element).
- **Reference**: A highlighted section labeled "<s>Reference:" before Memory 4.
- **Token Spans**:
- "span 128 tokens in parallel" (under Memory 0–4).
- "64 tokens" (under Chunk C and decoding).
### Legend/Color Coding
- **Orange**: `<s>Reference:` block.
- **Blue**: Memory blocks (Memory 0–4).
- **Green**: Chunks (Chunk 0, ..., Chunk C).
- **Dashed Blue**: Highlighted "Chunk C" and decoding stage.
### Detailed Analysis
1. **Memory Flow**:
- Memory blocks (0–4) are sequentially connected to the memory bank, suggesting data aggregation or transfer.
- The memory bank’s 3x4 grid implies structured storage or parallel access.
2. **Chunk Processing**:
- Chunks are processed sequentially (Chunk 0 → ... → Chunk C), with Chunk C emphasized via a dashed box.
- The transition from "..." to "Chunk C" suggests intermediate steps omitted for brevity.
3. **Token Spans**:
- Parallel processing of 128 tokens occurs upstream (Memory 0–4).
- Decoding stage processes 64 tokens, half the parallel span, indicating a reduction in data granularity.
4. **Reference Section**:
- The `<s>Reference:` block precedes Memory 4, possibly denoting a starting point or anchor for data retrieval.
### Key Observations
- **Flow Direction**: Data moves left-to-right (Memory blocks → Memory Bank → Chunks → Decoding).
- **Parallelism**: 128-token parallelism contrasts with 64-token sequential decoding, hinting at optimization for specific stages.
- **Chunk C Focus**: The dashed box around "Chunk C" may indicate a critical or current processing phase.
### Interpretation
This diagram likely represents a **data pipeline for large-scale token processing**, such as in machine learning or natural language processing. Key insights:
1. **Memory Hierarchy**: Memory blocks feed into a centralized memory bank, suggesting centralized data management before chunking.
2. **Chunking Strategy**: Data is divided into chunks (e.g., 64 tokens) for sequential decoding, balancing parallelism and sequential processing.
3. **Token Span Reduction**: The 128→64 token reduction implies compression or hierarchical processing, common in transformer models or attention mechanisms.
4. **Reference Anchor**: The `<s>` tag (often used in tokenization) marks a starting point, possibly for sequence alignment or context anchoring.
The pipeline emphasizes **efficiency in handling large datasets**, with parallel memory access followed by staged, chunked decoding. The dashed highlight on "Chunk C" may indicate dynamic or adaptive processing, where specific chunks are prioritized based on context.