# Technical Document Extraction: Transformer Attention Mechanism
## Diagram Overview
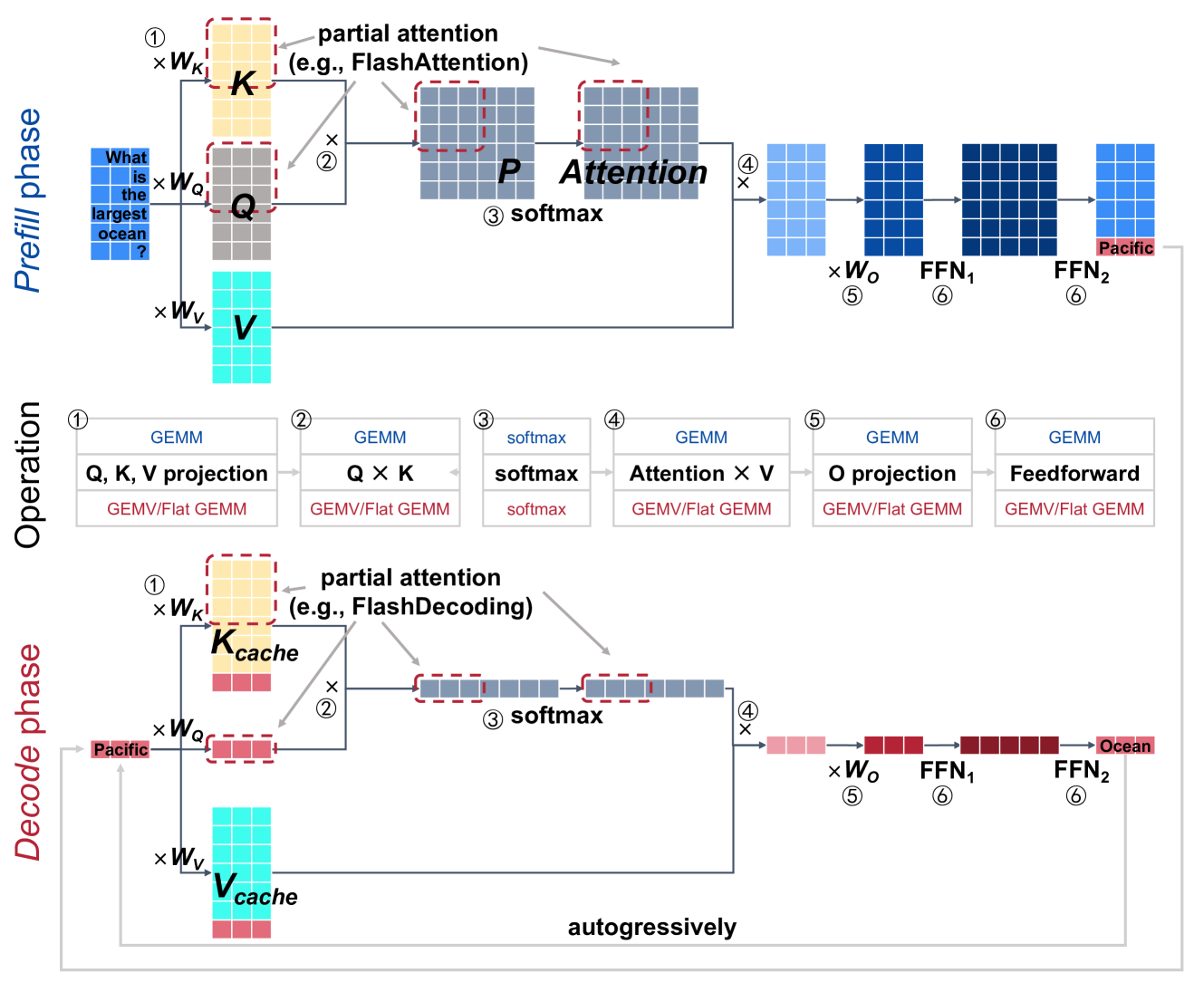
The image depicts a two-phase transformer model architecture with attention mechanisms, split into **Prefill phase** and **Decode phase**. The diagram uses color-coded matrices and labeled operations to illustrate data flow.
---
### **Legend & Color Coding**
- **Q (Query)**: Blue matrices
- **K (Key)**: Gray matrices
- **V (Value)**: Cyan matrices
- **O (Output)**: Dark blue matrices
- **FFN (Feedforward Network)**: Dark red matrices
- **Attention**: Light blue matrices
- **Softmax**: Light gray matrices
---
### **Prefill Phase**
#### Components & Flow
1. **Input Matrices**
- `Q` (blue), `K` (gray), `V` (cyan) matrices are initialized with weights `W_Q`, `W_K`, `W_V`.
2. **Partial Attention**
- `K` matrix undergoes partial attention (e.g., FlashAttention), reducing computational complexity.
3. **Attention Operation**
- **Step 1**: `Q × K` (GEMM operation)
- *GEMM*: General Matrix Multiply
- *GEMV/Flat GEMM*: Optimized variants
- **Step 2**: `softmax` applied to `Q × K`
- **Step 3**: `Attention × V` (GEMM)
- **Step 4**: `O projection` (GEMV/Flat GEMM)
- **Step 5**: `Feedforward` (GEMV/Flat GEMM)
#### Output
- Final output matrix labeled **"Pacific"** (example input: "What is the largest ocean?").
---
### **Decode Phase**
#### Components & Flow
1. **Cached Matrices**
- `K_cache` (gray) and `V_cache` (cyan) store precomputed keys and values for autoregressive decoding.
2. **Partial Attention**
- `K_cache` undergoes partial attention (e.g., FlashDecoding).
3. **Attention Operation**
- **Step 1**: `Q × K_cache` (GEMM)
- **Step 2**: `softmax` applied to `Q × K_cache`
- **Step 3**: `Attention × V_cache` (GEMM)
- **Step 4**: `O projection` (GEMV/Flat GEMM)
- **Step 5**: `Feedforward` (GEMV/Flat GEMM)
#### Output
- Final output matrix labeled **"Ocean"** (example input: "Pacific").
---
### **Key Observations**
1. **Autoregressive Decoding**:
- The Decode phase reuses cached `K` and `V` matrices to avoid recomputation, enabling efficient token generation.
2. **Optimized Operations**:
- `GEMV/Flat GEMM` replaces standard matrix operations for efficiency.
3. **Partial Attention**:
- Reduces memory and compute costs by focusing on relevant tokens (e.g., FlashAttention/FlashDecoding).
---
### **Spatial Grounding & Validation**
- **Legend Position**: Left-aligned, with colors matching matrix labels.
- **Trend Verification**:
- Prefill phase flows linearly from input matrices to output.
- Decode phase reuses cached data, avoiding redundant computations.
- **Component Isolation**:
- Prefill and Decode phases are distinct but share similar operations (e.g., GEMM, softmax).
---
### **Textual Transcription**
All text in the diagram is in **English**. No non-English content detected.
---
### **Conclusion**
The diagram illustrates a transformer model optimized for efficiency via partial attention and matrix operation optimizations. The Prefill phase processes input tokens, while the Decode phase generates outputs autoregressively using cached data.