\n
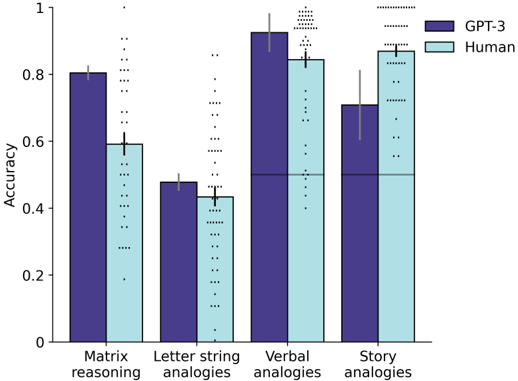
## Bar Chart: Accuracy Comparison - GPT-3 vs. Human
### Overview
This bar chart compares the accuracy of GPT-3 and human performance across four different types of analogies: Matrix reasoning, Letter string analogies, Verbal analogies, and Story analogies. Each analogy type has two bars representing the accuracy of GPT-3 and a human, with error bars indicating the variability in the results.
### Components/Axes
* **X-axis:** Analogy Type (Matrix reasoning, Letter string analogies, Verbal analogies, Story analogies)
* **Y-axis:** Accuracy (Scale from 0 to 1)
* **Legend:**
* Dark Purple: GPT-3
* Light Blue: Human
* **Error Bars:** Represent the variability/standard deviation of the accuracy scores. They are represented by dotted lines extending vertically from each bar.
### Detailed Analysis
Let's analyze each analogy type individually, noting the approximate values based on the chart:
1. **Matrix Reasoning:**
* GPT-3: The dark purple bar slopes downward slightly from left to right. Accuracy is approximately 0.82. The error bar extends from approximately 0.75 to 0.89.
* Human: The light blue bar is lower than GPT-3. Accuracy is approximately 0.60. The error bar extends from approximately 0.53 to 0.67.
2. **Letter String Analogies:**
* GPT-3: The dark purple bar is relatively low. Accuracy is approximately 0.48. The error bar extends from approximately 0.41 to 0.55.
* Human: The light blue bar is slightly higher than GPT-3. Accuracy is approximately 0.43. The error bar extends from approximately 0.36 to 0.50.
3. **Verbal Analogies:**
* GPT-3: The dark purple bar is the highest on the chart. Accuracy is approximately 0.92. The error bar extends from approximately 0.85 to 0.99.
* Human: The light blue bar is slightly lower than GPT-3. Accuracy is approximately 0.86. The error bar extends from approximately 0.79 to 0.93.
4. **Story Analogies:**
* GPT-3: The dark purple bar is lower than Verbal Analogies, but higher than the other two. Accuracy is approximately 0.72. The error bar extends from approximately 0.65 to 0.79.
* Human: The light blue bar is higher than GPT-3. Accuracy is approximately 0.84. The error bar extends from approximately 0.77 to 0.91.
### Key Observations
* GPT-3 consistently outperforms humans in Matrix Reasoning and Verbal Analogies.
* Humans outperform GPT-3 in Story Analogies.
* In Letter String Analogies, the performance of GPT-3 and humans is relatively similar, with GPT-3 having a slightly higher accuracy.
* The error bars indicate that the variability in human performance is generally comparable to or slightly less than that of GPT-3.
* The largest difference in accuracy between GPT-3 and humans is observed in Verbal Analogies.
### Interpretation
The data suggests that GPT-3 excels at tasks requiring formal reasoning and pattern recognition (Matrix Reasoning, Verbal Analogies), while humans demonstrate a stronger ability in tasks requiring contextual understanding and narrative reasoning (Story Analogies). The relatively similar performance in Letter String Analogies suggests that this task may rely on a combination of both types of reasoning.
The error bars provide insight into the consistency of performance. The overlap between the error bars for some analogy types indicates that the difference in accuracy between GPT-3 and humans may not be statistically significant in those cases.
The chart highlights the strengths and weaknesses of GPT-3 compared to human intelligence, suggesting that while GPT-3 can perform well on certain types of reasoning tasks, it still lags behind humans in areas requiring nuanced understanding of context and narrative. This could be due to the different ways in which GPT-3 and humans process information – GPT-3 relies on statistical patterns in data, while humans leverage real-world knowledge and experience.