## Bar Chart: GPT-3 vs. Human Accuracy on Analogy Tasks
### Overview
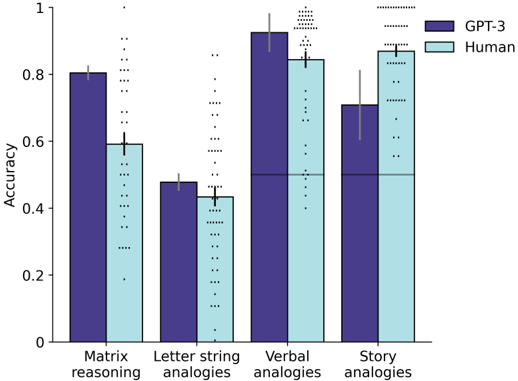
The image is a grouped bar chart comparing the accuracy of two entities, "GPT-3" and "Human," across four different analogy-based reasoning tasks. The chart includes error bars and scattered data points for each condition, indicating variability in performance.
### Components/Axes
* **Chart Type:** Grouped bar chart with overlaid scatter points and error bars.
* **Y-Axis:** Labeled "Accuracy." The scale runs from 0 to 1, with major tick marks at 0, 0.2, 0.4, 0.6, 0.8, and 1.
* **X-Axis:** Four categorical task types are listed:
1. Matrix reasoning
2. Letter string analogies
3. Verbal analogies
4. Story analogies
* **Legend:** Located in the top-right corner of the chart area.
* **Dark Purple Bar:** Labeled "GPT-3"
* **Light Blue Bar:** Labeled "Human"
* **Visual Elements:**
* Each task category has two adjacent bars (GPT-3 left, Human right).
* A thin black vertical line (error bar) extends from the top of each bar.
* Numerous small black dots are scattered vertically above each bar, likely representing individual data points or trials.
### Detailed Analysis
**1. Matrix reasoning:**
* **Trend:** GPT-3 shows higher accuracy than Human.
* **GPT-3 (Dark Purple):** Accuracy is approximately **0.80**. The error bar extends from roughly 0.78 to 0.82.
* **Human (Light Blue):** Accuracy is approximately **0.60**. The error bar extends from roughly 0.58 to 0.62.
* **Data Points:** A dense cluster of dots is visible above both bars, spanning from below 0.2 to above 1.0 for GPT-3, and from ~0.2 to ~0.9 for Human.
**2. Letter string analogies:**
* **Trend:** GPT-3 shows slightly higher accuracy than Human.
* **GPT-3 (Dark Purple):** Accuracy is approximately **0.48**. The error bar extends from roughly 0.46 to 0.50.
* **Human (Light Blue):** Accuracy is approximately **0.43**. The error bar extends from roughly 0.41 to 0.45.
* **Data Points:** Dots are scattered above both bars, ranging from ~0.1 to ~0.9.
**3. Verbal analogies:**
* **Trend:** GPT-3 shows higher accuracy than Human. This is the highest accuracy for GPT-3 across all tasks.
* **GPT-3 (Dark Purple):** Accuracy is approximately **0.92**. The error bar extends from roughly 0.90 to 0.94.
* **Human (Light Blue):** Accuracy is approximately **0.85**. The error bar extends from roughly 0.83 to 0.87.
* **Data Points:** A very dense cluster of dots is visible above both bars, concentrated near the top of the scale (0.8 to 1.0).
**4. Story analogies:**
* **Trend:** Human shows higher accuracy than GPT-3. This is the only task where Human performance exceeds GPT-3.
* **GPT-3 (Dark Purple):** Accuracy is approximately **0.71**. The error bar extends from roughly 0.69 to 0.73.
* **Human (Light Blue):** Accuracy is approximately **0.87**. The error bar extends from roughly 0.85 to 0.89.
* **Data Points:** Dots are scattered above both bars, with a dense cluster for Human near the top.
### Key Observations
1. **Performance Reversal:** The relative performance of GPT-3 and Human flips between task types. GPT-3 leads in Matrix, Letter string, and Verbal analogies, while Human leads in Story analogies.
2. **Highest & Lowest Scores:** The highest overall accuracy is achieved by GPT-3 on Verbal analogies (~0.92). The lowest overall accuracy is by Human on Letter string analogies (~0.43).
3. **Variability:** The scattered dots indicate significant trial-to-trial variability for both entities across all tasks. The error bars suggest the mean accuracy estimates are relatively precise.
4. **Task Difficulty:** Based on the combined performance, "Letter string analogies" appears to be the most difficult task (lowest accuracies), while "Verbal analogies" appears to be the easiest (highest accuracies).
### Interpretation
The data suggests a dissociation in cognitive strengths between the AI model (GPT-3) and humans. GPT-3 demonstrates superior performance on tasks that may rely more on structured pattern recognition and formal linguistic rules (Matrix reasoning, Letter string, Verbal analogies). In contrast, humans outperform GPT-3 on "Story analogies," a task likely requiring deeper narrative comprehension, contextual integration, and perhaps real-world knowledge that is less formally structured.
This pattern implies that while the model excels at certain types of abstract and verbal reasoning, human cognition retains an advantage in tasks grounded in narrative and contextual understanding. The high variability (scattered dots) for both groups indicates that performance on these analogy tasks is not uniform and can fluctuate significantly from one instance to another. The chart effectively highlights that "accuracy" on analogy tasks is not a monolithic measure but is highly dependent on the specific cognitive demands of the task format.