## Bar Chart: GPT-3 vs Human Accuracy Across Cognitive Tasks
### Overview
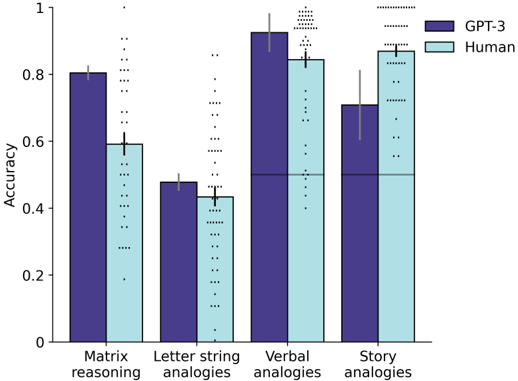
The chart compares the accuracy of GPT-3 and human performance across four cognitive tasks: Matrix reasoning, Letter string analogies, Verbal analogies, and Story analogies. Accuracy is measured on a scale from 0 to 1, with error bars indicating variability.
### Components/Axes
- **Y-axis**: Accuracy (0 to 1, increments of 0.2)
- **X-axis**: Tasks (Matrix reasoning, Letter string analogies, Verbal analogies, Story analogies)
- **Legend**:
- Dark blue: GPT-3
- Light blue: Human
- **Error bars**: Vertical lines atop bars showing standard deviation
### Detailed Analysis
1. **Matrix reasoning**:
- GPT-3: ~0.80 (±0.05)
- Human: ~0.60 (±0.10)
2. **Letter string analogies**:
- GPT-3: ~0.48 (±0.05)
- Human: ~0.45 (±0.07)
3. **Verbal analogies**:
- GPT-3: ~0.92 (±0.03)
- Human: ~0.85 (±0.05)
4. **Story analogies**:
- GPT-3: ~0.70 (±0.10)
- Human: ~0.88 (±0.05)
### Key Observations
- GPT-3 outperforms humans in **Matrix reasoning** (+0.20) and **Verbal analogies** (+0.07).
- Humans excel in **Story analogies** (+0.18) despite GPT-3's higher variability (±0.10 vs ±0.05).
- **Letter string analogies** show near-parity (GPT-3: 0.48 vs Human: 0.45).
- Error bars suggest greater uncertainty in GPT-3's performance on **Story analogies** and human performance on **Matrix reasoning**.
### Interpretation
The data reveals a clear pattern: GPT-3 dominates in structured, rule-based tasks (Matrix/Verbal analogies) but struggles with complex, narrative-driven tasks (Story analogies) where human intuition prevails. The error bars highlight that GPT-3's performance on Story analogies is less reliable, possibly due to the model's difficulty in capturing contextual nuances. Humans demonstrate superior adaptability in tasks requiring abstract reasoning beyond pattern recognition. This aligns with known limitations of large language models in handling open-ended, context-rich problems.