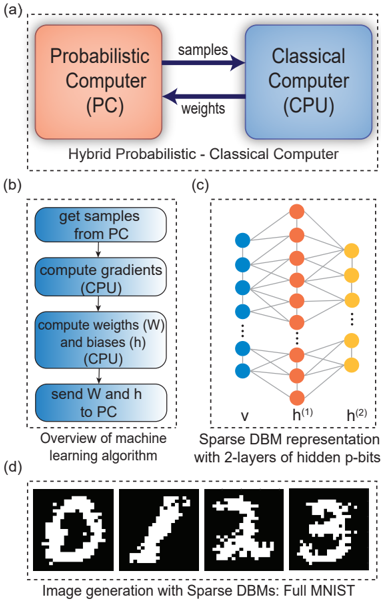
## Diagram: Hybrid Probabilistic-Classical Computer System for Machine Learning
### Overview
The image illustrates a hybrid probabilistic-classical computing architecture for machine learning, combining probabilistic sampling (PC) with classical computation (CPU). It includes workflows for gradient computation, weight optimization, and sparse DBM (Deep Belief Machine) representations, culminating in image generation from the MNIST dataset.
---
### Components/Axes
#### (a) Hybrid System Architecture
- **Components**:
- **Probabilistic Computer (PC)**: Orange box labeled "Probabilistic Computer (PC)".
- **Classical Computer (CPU)**: Blue box labeled "Classical Computer (CPU)".
- **Data Flow**:
- **Samples**: Arrows from PC to CPU (labeled "samples").
- **Weights**: Arrows from CPU to PC (labeled "weights").
- **Label**: "Hybrid Probabilistic - Classical Computer".
#### (b) Machine Learning Workflow
- **Steps** (blue rounded rectangles):
1. **Get samples from PC**.
2. **Compute gradients (CPU)**.
3. **Compute weights (W) and biases (h) (CPU)**.
4. **Send W and h to PC**.
- **Label**: "Overview of machine learning algorithm".
#### (c) Sparse DBM Representation
- **Structure**:
- **Nodes**:
- **Input Layer**: Blue nodes labeled "v".
- **Hidden Layers**: Orange nodes labeled "h^(1)" and "h^(2)".
- **Output Layer**: Yellow nodes (no explicit label).
- **Connections**: Fully connected between layers (dashed lines).
- **Label**: "Sparse DBM representation with 2-layers of hidden p-bits".
#### (d) Image Generation
- **Examples**: Four black-and-white pixelated digits (0, 1, 2, 3).
- **Caption**: "Image generation with Sparse DBMs: Full MNIST".
---
### Detailed Analysis
#### (a) Hybrid System
- The PC generates probabilistic samples, which are processed by the CPU to compute gradients and update weights/biases. These updated parameters are then fed back to the PC, creating an iterative optimization loop.
#### (b) Workflow
- The algorithm alternates between probabilistic sampling (PC) and classical optimization (CPU), typical of contrastive divergence or Gibbs sampling in DBMs.
#### (c) Sparse DBM
- The 2-layer hidden p-bit architecture reduces computational complexity compared to full DBMs. The sparse connectivity (dashed lines) implies probabilistic dependencies between nodes.
#### (d) MNIST Generation
- The generated digits demonstrate the system's ability to reconstruct handwritten numerals, validating the effectiveness of the hybrid approach.
---
### Key Observations
1. **Bidirectional Data Flow**: The PC and CPU collaborate iteratively, with samples flowing to the CPU for gradient computation and updated parameters returning to the PC.
2. **Sparse Connectivity**: The DBM's sparse representation (orange/blue/yellow nodes) reduces memory and computational requirements.
3. **MNIST Validation**: The generated digits (0-3) confirm the system's capability for image synthesis.
---
### Interpretation
This hybrid architecture leverages the strengths of probabilistic sampling (exploration of high-dimensional spaces) and classical optimization (efficient gradient descent). The sparse DBM representation balances model complexity and computational efficiency, enabling practical deployment on hybrid hardware. The MNIST results suggest the system can generalize to real-world datasets, though scalability to larger images or datasets would require further optimization of the sparse connectivity and sampling strategies.