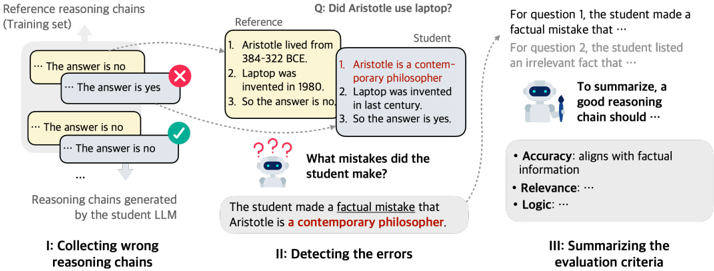
## Diagram: Reasoning Chain Evaluation
### Overview
The image illustrates a process for evaluating the reasoning chains generated by a student Large Language Model (LLM). It involves collecting wrong reasoning chains, detecting errors, and summarizing the evaluation criteria. The diagram compares reference reasoning chains with those produced by the student LLM, highlighting factual inaccuracies and irrelevant information.
### Components/Axes
* **Title:** Q: Did Aristotle use laptop?
* **Sections:** The diagram is divided into three sections, labeled I, II, and III.
* I: Collecting wrong reasoning chains
* II: Detecting the errors
* III: Summarizing the evaluation criteria
* **Reference Reasoning Chains (Training set):** Located in the top-left corner. Contains example reasoning chains.
* **Reasoning chains generated by the student LLM:** Located below the "Reference Reasoning Chains".
* **Reference:** A box containing factual statements.
* 1. Aristotle lived from 384-322 BCE.
* 2. Laptop was invented in 1980.
* 3. So the answer is no.
* **Student:** A box containing the student LLM's reasoning.
* 1. Aristotle is a contemporary philosopher.
* 2. Laptop was invented in last century.
* 3. So the answer is yes.
* **Error Detection:** A question mark icon with the text "What mistakes did the student make?"
* **Error Summary:** "The student made a factual mistake that Aristotle is a contemporary philosopher."
* **Evaluation Criteria:**
* Accuracy: aligns with factual information
* Relevance: ...
* Logic: ...
### Detailed Analysis
* **Section I: Collecting wrong reasoning chains:**
* Shows a series of reasoning chains. Some are marked with a red "X" indicating an error, while others are marked with a green checkmark indicating correctness.
* Example reasoning chains include phrases like "... The answer is no" and "... The answer is yes".
* **Section II: Detecting the errors:**
* Compares the "Reference" and "Student" reasoning.
* The "Reference" provides factual information: Aristotle's lifespan and the invention year of the laptop.
* The "Student" provides incorrect reasoning: stating Aristotle is a contemporary philosopher and misdating the laptop invention.
* The error summary highlights the factual mistake regarding Aristotle.
* **Section III: Summarizing the evaluation criteria:**
* Lists the criteria for evaluating reasoning chains: Accuracy, Relevance, and Logic.
* Provides a partial description of Accuracy: "aligns with factual information".
### Key Observations
* The diagram focuses on identifying and categorizing errors in the reasoning chains generated by an LLM.
* The comparison between "Reference" and "Student" reasoning is central to the error detection process.
* The evaluation criteria emphasize the importance of factual accuracy, relevance, and logical consistency.
### Interpretation
The diagram illustrates a method for evaluating the quality of reasoning chains produced by a student LLM. It highlights the importance of comparing the LLM's reasoning with factual information to identify errors. The process involves collecting examples of incorrect reasoning, pinpointing the specific mistakes made by the LLM, and summarizing the key criteria for evaluating reasoning chains. The diagram suggests that a good reasoning chain should be accurate, relevant, and logically sound. The example provided shows the LLM making a factual error by mischaracterizing Aristotle as a contemporary philosopher, demonstrating the need for rigorous evaluation of LLM-generated content.