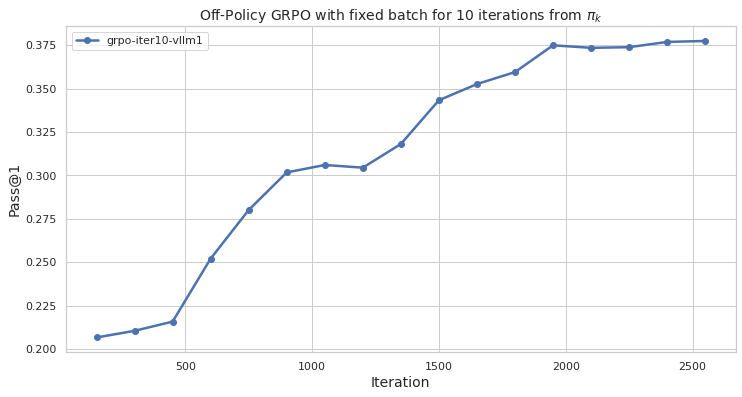
## Line Chart: Off-Policy GRPO with fixed batch for 10 iterations from π_k
### Overview
The chart depicts the performance of an off-policy GRPO (Generalized Reinforcement Policy Optimization) algorithm with a fixed batch size over 2500 iterations. The metric measured is "Pass@1," which likely represents task success or accuracy. The line shows a steady increase in performance, plateauing near the end of the iteration range.
### Components/Axes
- **X-axis (Horizontal)**: Labeled "iteration," with markers at 0, 500, 1000, 1500, 2000, and 2500.
- **Y-axis (Vertical)**: Labeled "Pass@1," with increments of 0.025 from 0.200 to 0.375.
- **Legend**: Located in the top-left corner, labeled "grpo-iter10-vllm1" with a blue line marker.
- **Line**: A single blue line representing the "grpo-iter10-vllm1" series, plotted with markers at each iteration interval.
### Detailed Analysis
- **Initial Phase (0–500 iterations)**:
- Pass@1 starts at approximately **0.205** (iteration 0).
- Rises sharply to **0.215** by iteration 500.
- **Mid-Phase (500–1500 iterations)**:
- Accelerates to **0.300** by iteration 1000.
- Reaches **0.320** at iteration 1500.
- **Late Phase (1500–2500 iterations)**:
- Slows growth, peaking at **0.375** by iteration 2000.
- Stabilizes near **0.375** for iterations 2000–2500.
### Key Observations
1. **Rapid Initial Improvement**: The steepest growth occurs between iterations 0–1000, suggesting early optimization gains.
2. **Plateau at High Performance**: After iteration 2000, performance stabilizes, indicating convergence or diminishing returns.
3. **Consistent Trend**: No dips or anomalies observed; the line is monotonically increasing.
### Interpretation
The data suggests that the GRPO algorithm with a fixed batch size achieves significant performance improvements within the first 1000 iterations, with diminishing returns thereafter. The plateau at ~0.375 Pass@1 implies that the model may have reached an optimal policy or that the fixed batch size limits further exploration. This could inform hyperparameter tuning (e.g., adjusting batch size) or termination criteria for similar optimization tasks. The absence of noise in the line suggests stable training dynamics, though real-world scenarios might exhibit variability not captured here.