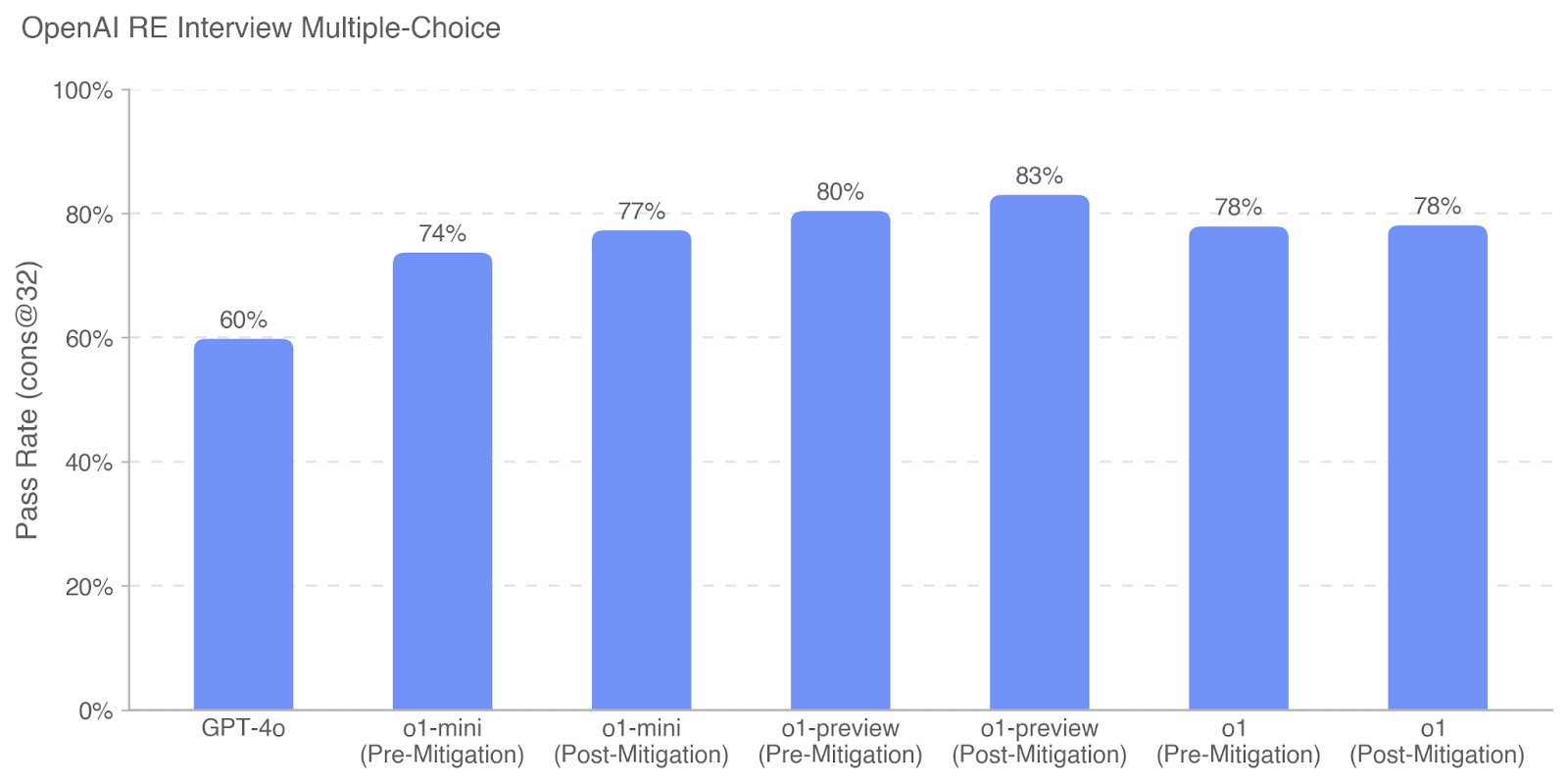
## Bar Chart: OpenAI RE Interview Multiple-Choice Pass Rates
### Overview
This is a vertical bar chart comparing the performance of different AI models on a multiple-choice interview assessment. The chart is titled "OpenAI RE Interview Multiple-Choice" and displays the "Pass Rate (cons @32)" for seven distinct model configurations. The data suggests an evaluation of model capabilities, potentially before and after applying a "mitigation" technique.
### Components/Axes
* **Title:** "OpenAI RE Interview Multiple-Choice" (located at the top-left of the chart area).
* **Y-Axis:**
* **Label:** "Pass Rate (cons @32)" (rotated vertically on the left side).
* **Scale:** Linear scale from 0% to 100%.
* **Major Tick Marks:** 0%, 20%, 40%, 60%, 80%, 100%.
* **Grid Lines:** Horizontal dashed lines extend from each major tick mark across the chart.
* **X-Axis:**
* **Categories (from left to right):**
1. GPT-4o
2. o1-mini (Pre-Mitigation)
3. o1-mini (Post-Mitigation)
4. o1-preview (Pre-Mitigation)
5. o1-preview (Post-Mitigation)
6. o1 (Pre-Mitigation)
7. o1 (Post-Mitigation)
* **Data Series:** A single series represented by seven solid, medium-blue bars. There is no separate legend, as the category labels are placed directly below each bar.
* **Data Labels:** The exact pass rate percentage is displayed above each bar.
### Detailed Analysis
The chart presents the following pass rate data for each model configuration:
1. **GPT-4o:** 60%
2. **o1-mini (Pre-Mitigation):** 74%
3. **o1-mini (Post-Mitigation):** 77%
4. **o1-preview (Pre-Mitigation):** 80%
5. **o1-preview (Post-Mitigation):** 83%
6. **o1 (Pre-Mitigation):** 78%
7. **o1 (Post-Mitigation):** 78%
**Trend Verification:**
* The general trend from left to right is an increase in pass rate from GPT-4o to the o1-preview models, followed by a slight decrease for the o1 models.
* For the "o1-mini" and "o1-preview" model families, the "Post-Mitigation" configuration shows a higher pass rate than its "Pre-Mitigation" counterpart.
* For the "o1" model, the pass rate is identical (78%) for both Pre- and Post-Mitigation states.
### Key Observations
* **Highest Performer:** The `o1-preview (Post-Mitigation)` model achieved the highest pass rate at 83%.
* **Lowest Performer:** The `GPT-4o` model had the lowest pass rate at 60%.
* **Mitigation Impact:** Applying "mitigation" resulted in a positive performance increase of +3 percentage points for `o1-mini` (74% to 77%) and +3 percentage points for `o1-preview` (80% to 83%). It had no net effect on the `o1` model.
* **Model Family Performance:** Within the displayed set, the `o1-preview` models outperformed both `o1-mini` and the base `o1` models, regardless of mitigation status.
* **Baseline Comparison:** All six "o1" family model configurations (mini, preview, base) significantly outperformed the `GPT-4o` baseline, with pass rates ranging from 74% to 83% compared to 60%.
### Interpretation
This chart likely illustrates the results of an internal benchmarking exercise for reverse engineering (RE) or technical interview-style multiple-choice questions. The data suggests several key points:
1. **Model Evolution:** There is a clear performance hierarchy, with the newer "o1" series models demonstrating substantially higher pass rates than GPT-4o on this specific task. The "preview" variant appears to be the most capable within this evaluation.
2. **Effect of Mitigation:** The "mitigation" technique being tested appears to be beneficial for the `o1-mini` and `o1-preview` models, providing a consistent, modest performance boost. The lack of change for the `o1` model could indicate that this technique was already incorporated, is ineffective for this model variant, or that the model had already reached a performance ceiling on this task.
3. **Task Specificity:** The metric "Pass Rate (cons @32)" is specific. "cons @32" likely refers to a consistency metric (e.g., achieving a correct answer in 32 attempts or a similar technical parameter). The high pass rates (74-83%) for the o1 series suggest these models are quite proficient at this particular style of technical multiple-choice assessment.
4. **Strategic Implication:** The results would be valuable for deciding which model to deploy for tasks resembling this interview format or for guiding further development of the "mitigation" process. The identical pre/post result for `o1` warrants investigation to understand why the intervention had no effect.