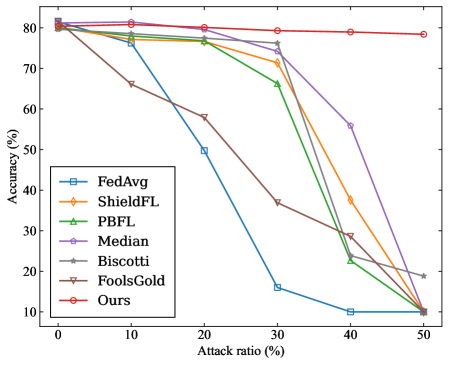
## Line Chart: Accuracy vs. Attack Ratio for Federated Learning Defenses
### Overview
This line chart depicts the accuracy of several Federated Learning (FL) defense mechanisms as a function of the attack ratio. The x-axis represents the attack ratio (percentage of compromised clients), and the y-axis represents the accuracy (percentage). The chart compares the performance of FedAvg, ShieldFL, PBFL, Median, Biscotti, FoolsGold, and a method labeled "Ours".
### Components/Axes
* **X-axis:** "Attack ratio (%)" - Scale ranges from 0% to 50%, with markers at 0, 10, 20, 30, 40, and 50.
* **Y-axis:** "Accuracy (%)" - Scale ranges from 0% to 80%, with markers at 10, 20, 30, 40, 50, 60, 70, and 80.
* **Legend:** Located in the bottom-left corner. Contains the following labels and corresponding colors:
* FedAvg (Blue)
* ShieldFL (Orange)
* PBFL (Green)
* Median (Purple)
* Biscotti (Grey)
* FoolsGold (Pink)
* Ours (Red)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points, verified against the legend colors:
* **FedAvg (Blue):** Starts at approximately 81% accuracy at 0% attack ratio. The line slopes sharply downward, reaching approximately 52% at 20% attack ratio, 12% at 40% attack ratio, and approximately 8% at 50% attack ratio.
* **ShieldFL (Orange):** Starts at approximately 79% accuracy at 0% attack ratio. The line initially decreases slightly, then remains relatively stable until approximately 30% attack ratio (around 70% accuracy). After 30%, it declines rapidly, reaching approximately 18% at 50% attack ratio.
* **PBFL (Green):** Starts at approximately 78% accuracy at 0% attack ratio. The line decreases steadily, reaching approximately 68% at 20% attack ratio, 40% at 40% attack ratio, and approximately 10% at 50% attack ratio.
* **Median (Purple):** Starts at approximately 80% accuracy at 0% attack ratio. The line decreases gradually, reaching approximately 75% at 20% attack ratio, 56% at 40% attack ratio, and approximately 15% at 50% attack ratio.
* **Biscotti (Grey):** Starts at approximately 78% accuracy at 0% attack ratio. The line decreases steadily, reaching approximately 65% at 20% attack ratio, 35% at 40% attack ratio, and approximately 18% at 50% attack ratio.
* **FoolsGold (Pink):** Starts at approximately 78% accuracy at 0% attack ratio. The line remains relatively stable until approximately 30% attack ratio (around 76% accuracy). After 30%, it declines, reaching approximately 20% at 50% attack ratio.
* **Ours (Red):** Starts at approximately 81% accuracy at 0% attack ratio. The line remains almost flat, maintaining approximately 78-80% accuracy throughout the entire range of attack ratios (0% to 50%).
### Key Observations
* The "Ours" method demonstrates significantly higher accuracy compared to all other methods as the attack ratio increases. It maintains a stable accuracy level even at a 50% attack ratio.
* FedAvg is the most vulnerable to attacks, experiencing a rapid decline in accuracy with increasing attack ratios.
* ShieldFL and FoolsGold show some resilience up to a 30% attack ratio, but their accuracy drops significantly beyond that point.
* PBFL, Median, and Biscotti exhibit a more gradual decline in accuracy as the attack ratio increases, but still fall significantly below "Ours".
### Interpretation
The data suggests that the proposed "Ours" defense mechanism is substantially more robust against attacks in a Federated Learning environment than the other methods tested. The consistent high accuracy across all attack ratios indicates a strong ability to mitigate the impact of compromised clients. The stark contrast between "Ours" and FedAvg highlights the importance of implementing defense mechanisms in FL systems, as a naive approach (FedAvg) is highly susceptible to attacks. The varying degrees of resilience among ShieldFL, PBFL, Median, Biscotti, and FoolsGold suggest that different defense strategies offer varying levels of protection, and the optimal choice may depend on the specific threat model and system constraints. The fact that most methods degrade in performance as the attack ratio increases is expected, as a higher proportion of malicious clients can exert a greater influence on the global model. This chart provides compelling evidence for the effectiveness of the "Ours" method and underscores the critical need for robust defense mechanisms in Federated Learning.