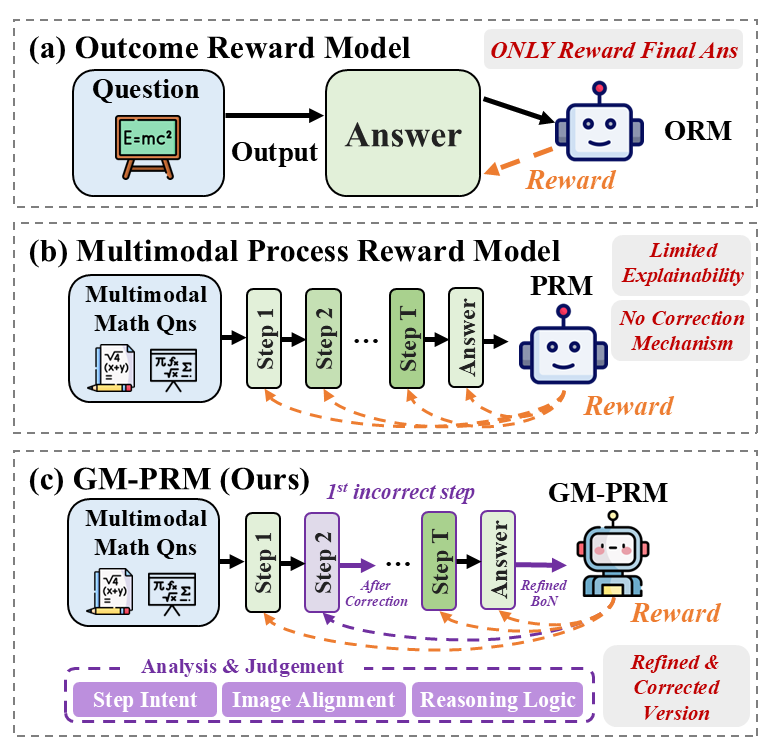
## Diagram: Comparison of Reward Model Architectures
### Overview
The image presents a comparative architectural diagram illustrating three distinct approaches to training reward models for AI systems, specifically in the context of multimodal mathematical reasoning. The diagram progresses from a basic Outcome Reward Model (ORM) to a standard Process Reward Model (PRM), and finally to the proposed "GM-PRM" (Generative Multimodal Process Reward Model), which introduces correction mechanisms.
### Components/Axes
The diagram is divided into three horizontal panels, each representing a different model architecture:
* **Panel (a): Outcome Reward Model (ORM)**
* **Input:** "Question" (represented by a chalkboard icon with $E=mc^2$).
* **Process:** "Answer" (green box).
* **Output:** Robot icon labeled "ORM".
* **Feedback:** Orange dashed arrow labeled "Reward" pointing from ORM to "Answer".
* **Annotation:** "ONLY Reward Final Ans" (red text, top-right).
* **Panel (b): Multimodal Process Reward Model (PRM)**
* **Input:** "Multimodal Math Qns" (represented by icons showing $\sqrt{4(x+y)}$ and $\pi \int \sqrt{x} \sum$).
* **Process:** A sequence of steps: "Step 1" (green), "Step 2" (green), "..." (ellipsis), "Step T" (green), "Answer" (green).
* **Output:** Robot icon labeled "PRM".
* **Feedback:** Multiple orange dashed arrows labeled "Reward" pointing from PRM to each individual step.
* **Annotations:** "Limited Explainability" and "No Correction Mechanism" (red text, top-right).
* **Panel (c): GM-PRM (Ours)**
* **Input:** "Multimodal Math Qns" (same as panel b).
* **Process:** A sequence of steps: "Step 1" (green), "Step 2" (purple, labeled "1st incorrect step"), "..." (ellipsis), "Step T" (green), "Answer" (green).
* **Transition:** An arrow labeled "After Correction" connects "Step 2" to "Step T".
* **Output:** Robot icon labeled "GM-PRM".
* **Feedback:** Orange dashed arrows from GM-PRM to steps; a purple dashed arrow from GM-PRM to "Step 2".
* **Annotations:** "Refined BoN" (Best-of-N) near the output arrow.
* **Footer (Bottom):** A dashed purple box labeled "Analysis & Judgement" containing three sub-components: "Step Intent", "Image Alignment", and "Reasoning Logic". A separate box to the right labeled "Refined & Corrected Version".
### Detailed Analysis
* **Panel (a) - ORM:** The flow is linear and singular. The model only evaluates the final output. The annotation "ONLY Reward Final Ans" confirms that intermediate reasoning steps are ignored.
* **Panel (b) - PRM:** The flow is granular. The model evaluates each step individually. However, the annotations "Limited Explainability" and "No Correction Mechanism" indicate that while the model can identify a bad step, it cannot rectify the reasoning path.
* **Panel (c) - GM-PRM:** This architecture introduces a branching or corrective logic.
* **Visual Indicator:** "Step 2" is highlighted in purple, indicating it is the "1st incorrect step."
* **Correction Flow:** The diagram shows a path "After Correction" that bypasses or modifies the sequence following the incorrect step.
* **Feedback Loop:** The purple dashed arrow from the GM-PRM robot back to "Step 2" suggests the model actively identifies and targets the error for correction.
* **Supporting Components:** The footer indicates that the GM-PRM relies on "Analysis & Judgement" (Step Intent, Image Alignment, Reasoning Logic) to produce a "Refined & Corrected Version."
### Key Observations
* **Evolution of Feedback:** The feedback mechanism evolves from a single point (ORM) to multiple points (PRM) to targeted, corrective feedback (GM-PRM).
* **Color Coding:** Green boxes represent standard/correct steps, while the purple box in panel (c) specifically denotes an error ("1st incorrect step").
* **Multimodal Integration:** The inclusion of "Image Alignment" in the footer of panel (c) suggests that the GM-PRM architecture is specifically designed to handle multimodal inputs (e.g., math problems involving images or complex notation) more effectively than the previous models.
### Interpretation
The diagram demonstrates a progression in AI reasoning evaluation.
1. **ORM** is depicted as insufficient for complex tasks because it treats the reasoning process as a "black box," only caring about the final result.
2. **PRM** improves upon this by evaluating intermediate steps, but the diagram highlights a critical failure mode: it lacks the ability to fix errors once they occur ("No Correction Mechanism").
3. **GM-PRM** is presented as the superior solution. It not only evaluates steps but actively performs "Analysis & Judgement" (using Step Intent, Image Alignment, and Reasoning Logic) to identify the "1st incorrect step" and apply a correction. This implies that GM-PRM is capable of iterative self-correction, leading to a "Refined & Corrected Version" of the reasoning path, which likely results in higher accuracy for complex multimodal mathematical problems.