## Diagram: Comparison of Reward Models
### Overview
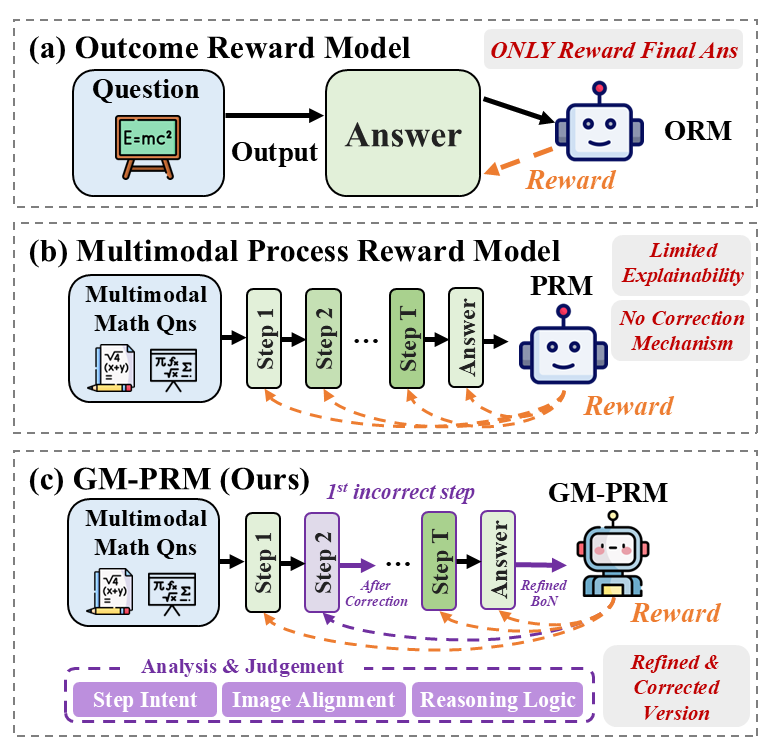
The image presents a comparative diagram illustrating three different reward models: Outcome Reward Model (ORM), Multimodal Process Reward Model (PRM), and GM-PRM (a proposed model). The diagram highlights the flow of information and the reward mechanisms associated with each model.
### Components/Axes
* **Title:** The image is divided into three sections, each representing a different reward model.
* (a) Outcome Reward Model
* (b) Multimodal Process Reward Model
* (c) GM-PRM (Ours)
* **Input:** Each model starts with an input.
* ORM: "Question" (represented by a blue box containing the equation E=mc²)
* PRM and GM-PRM: "Multimodal Math Qns" (represented by a blue box containing math equations)
* **Process:** The models process the input through a series of steps.
* ORM: A single "Output" arrow leading to "Answer" (green box).
* PRM and GM-PRM: A series of steps labeled "Step 1", "Step 2", ..., "Step T" (green boxes) leading to "Answer" (green box).
* **Reward:** Each model includes a reward mechanism.
* ORM, PRM, and GM-PRM: A robot icon labeled "ORM", "PRM", and "GM-PRM" respectively, receiving a "Reward" (orange dashed arrow).
* **Annotations:** Additional text annotations provide context and highlight key differences.
* ORM: "ONLY Reward Final Ans" (red text)
* PRM: "Limited Explainability", "No Correction Mechanism" (red text)
* GM-PRM: "1st incorrect step" (purple text), "After Correction" (purple arrow), "Refined BoN" (green text), "Refined & Corrected Version" (purple text)
* **Analysis & Judgement (GM-PRM):** A purple box at the bottom of the GM-PRM section contains the labels "Step Intent", "Image Alignment", and "Reasoning Logic".
### Detailed Analysis
**Outcome Reward Model (ORM):**
* The model takes a "Question" as input.
* The question is processed to produce an "Answer".
* The "ORM" agent receives a "Reward" only based on the final answer.
* The annotation "ONLY Reward Final Ans" emphasizes that the reward is solely based on the outcome.
**Multimodal Process Reward Model (PRM):**
* The model takes "Multimodal Math Qns" as input.
* The input is processed through a series of steps: "Step 1", "Step 2", ..., "Step T".
* The final step leads to an "Answer".
* The "PRM" agent receives a "Reward" based on the process.
* The annotations "Limited Explainability" and "No Correction Mechanism" highlight the limitations of this model.
**GM-PRM (Ours):**
* The model takes "Multimodal Math Qns" as input.
* The input is processed through a series of steps: "Step 1", "Step 2" (purple), ..., "Step T".
* The annotation "1st incorrect step" indicates a point where a correction mechanism is applied.
* The "After Correction" arrow shows the flow after a correction.
* The final step leads to an "Answer".
* The "GM-PRM" agent receives a "Reward" based on the refined process.
* The "Refined BoN" annotation suggests a refined version of something (likely a "Bag of Neurons" or similar concept).
* The "Refined & Corrected Version" annotation emphasizes the improvements made in this model.
* The "Analysis & Judgement" box indicates the model's ability to analyze and judge the steps involved.
### Key Observations
* The ORM is the simplest model, focusing only on the final outcome.
* The PRM considers the process but lacks explainability and a correction mechanism.
* The GM-PRM builds upon the PRM by incorporating a correction mechanism and analysis/judgment capabilities.
### Interpretation
The diagram illustrates the evolution of reward models for problem-solving, particularly in the context of multimodal math questions. The GM-PRM model is presented as an improvement over existing models by incorporating a correction mechanism and analysis/judgment capabilities. This suggests that the GM-PRM is more robust and capable of handling complex problems compared to the ORM and PRM models. The "Refined BoN" annotation implies that the GM-PRM utilizes a more sophisticated approach to processing information and generating solutions. The diagram highlights the importance of considering the process and incorporating feedback mechanisms in reward models for complex tasks.