# Technical Document Analysis: Multimodal Math Problem-Solving Reward Models
## Overview
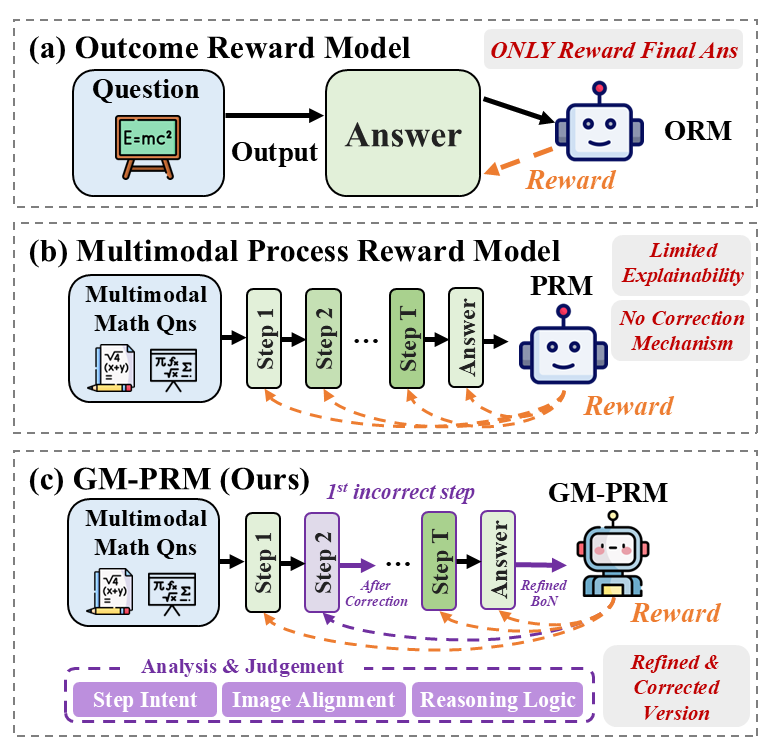
The image presents a comparative analysis of three reward models for evaluating multimodal math problem-solving processes. The diagram uses flowcharts with labeled components, directional arrows, and annotations to illustrate differences in reward mechanisms and correction capabilities.
---
## Diagram Components
### (a) Outcome Reward Model
**Title**: Outcome Reward Model
**Key Components**:
- **Question** (Input: Math equation "E=mc²")
- **Output** (Intermediate processing step)
- **Answer** (Final response)
- **ORM** (Robot icon with "Reward" arrow)
**Flow**:
```
Question → Output → Answer → Reward (only for final answers)
```
**Annotations**:
- Red text: "ONLY Reward Final Ans"
- ORM robot has a smiley face
---
### (b) Multimodal Process Reward Model
**Title**: Multimodal Process Reward Model
**Key Components**:
- **Multimodal Math Qns** (Input: Math problems with equations and diagrams)
- **Steps 1, 2, ..., T** (Intermediate reasoning steps)
- **Answer** (Final response)
- **PRM** (Robot icon with "Reward" arrow)
**Flow**:
```
Multimodal Math Qns → Step 1 → Step 2 → ... → Step T → Answer → Reward
```
**Annotations**:
- Red text box: "Limited Explainability"
- Red text box: "No Correction Mechanism"
- PRM robot has a neutral expression
---
### (c) GM-PRM (Ours)
**Title**: GM-PRM (Ours)
**Key Components**:
- **Multimodal Math Qns** (Input: Math problems with equations and diagrams)
- **Steps 1, 2, ..., T** (Intermediate reasoning steps)
- **1st incorrect step** (Highlighted with dashed arrow)
- **After Correction** (Dashed arrow indicating refinement)
- **Refined BoN** (Refined version of the answer)
- **GM-PRM** (Robot icon with "Reward" arrow)
**Flow**:
```
Multimodal Math Qns → Step 1 → Step 2 → ... → Step T → Answer → Reward
```
**Sub-process**:
```
Analysis & Judgement → Step Intent → Image Alignment → Reasoning Logic
```
**Annotations**:
- Red text: "Refined & Corrected Version"
- Dashed arrows indicate iterative refinement
- GM-PRM robot has a smiling face with cheeks
---
## Key Differences Between Models
| Feature | Outcome Reward Model (a) | Multimodal Process Reward Model (b) | GM-PRM (c) |
|------------------------|--------------------------|-------------------------------------|--------------------------------|
| **Reward Scope** | Final answer only | All steps | All steps + corrections |
| **Explainability** | Not specified | Limited | Improved through analysis |
| **Correction** | No | No | Yes (via "After Correction") |
| **Robot Icon** | ORM (smiley) | PRM (neutral) | GM-PRM (smiling with cheeks) |
---
## Spatial Grounding & Component Isolation
1. **Header**: Each section title (a, b, c) is bolded and positioned at the top of its respective flowchart.
2. **Main Chart**:
- Components are arranged left-to-right with vertical stacking for sub-processes (e.g., "Analysis & Judgement" in c).
- Arrows indicate sequential flow (solid for primary flow, dashed for corrections).
3. **Footer**: No explicit footer, but annotations are placed in red text boxes near relevant components.
---
## Trend Verification
- **No numerical data** present; trends are represented through structural differences in component connectivity and annotation emphasis.
---
## Conclusion
The diagram demonstrates a progression from simple outcome-based evaluation (a) to more sophisticated process-aware models (b and c). The proposed GM-PRM (c) introduces explicit correction mechanisms and multi-stage analysis, addressing limitations in explainability and adaptability observed in prior models.