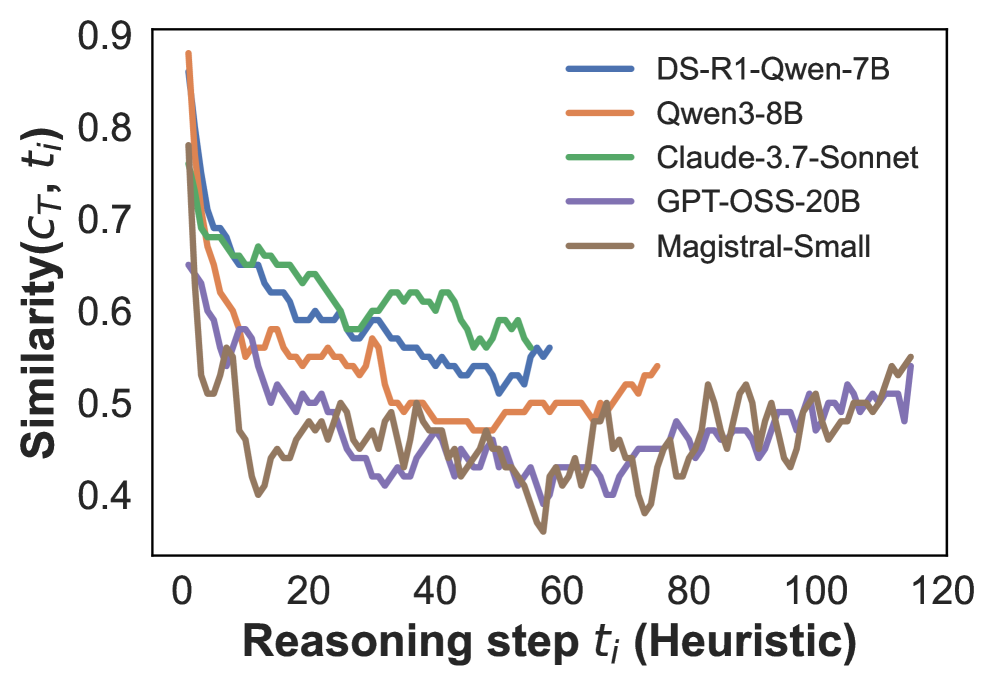
## Line Chart: Similarity vs. Reasoning Step
### Overview
This line chart depicts the similarity (Similarity(Cτ, t)) of several language models over reasoning steps (t). The x-axis represents the reasoning step, measured in a heuristic unit, ranging from 0 to approximately 120. The y-axis represents the similarity score, ranging from approximately 0.4 to 0.9. Five different language models are compared: DS-R1-Qwen-7B, Qwen3-8B, Claude-3.7-Sonnet, GPT-OSS-20B, and Magistral-Small.
### Components/Axes
* **X-axis:** "Reasoning step tᵢ (Heuristic)" - Ranges from 0 to 120.
* **Y-axis:** "Similarity(Cτ, t)" - Ranges from 0.4 to 0.9.
* **Legend (Top-Right):**
* DS-R1-Qwen-7B (Blue)
* Qwen3-8B (Orange)
* Claude-3.7-Sonnet (Green)
* GPT-OSS-20B (Purple)
* Magistral-Small (Grey)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points.
* **DS-R1-Qwen-7B (Blue):** The line starts at approximately 0.73 at step 0, rapidly decreases to around 0.58 by step 10, then plateaus and fluctuates between approximately 0.52 and 0.62 from step 40 to 120.
* **Qwen3-8B (Orange):** This line begins at approximately 0.75 at step 0, decreases sharply to around 0.55 by step 10, then gradually declines to approximately 0.50 by step 60. It then fluctuates between approximately 0.50 and 0.58 from step 60 to 120.
* **Claude-3.7-Sonnet (Green):** Starts at approximately 0.72 at step 0, decreases to around 0.60 by step 10, and then maintains a relatively stable level between approximately 0.58 and 0.65 from step 20 to 120.
* **GPT-OSS-20B (Purple):** Begins at approximately 0.70 at step 0, drops to around 0.45 by step 20, and then fluctuates between approximately 0.42 and 0.55 from step 20 to 120. This line exhibits the most volatility.
* **Magistral-Small (Grey):** Starts at approximately 0.71 at step 0, decreases rapidly to around 0.45 by step 20, and then fluctuates between approximately 0.40 and 0.55 from step 20 to 120. It shows a similar pattern to GPT-OSS-20B, but with slightly lower overall similarity scores.
All lines show an initial decrease in similarity as the reasoning step increases.
### Key Observations
* All models exhibit a decline in similarity as reasoning steps increase, suggesting that the initial coherence or alignment with the target concept diminishes with further reasoning.
* Claude-3.7-Sonnet demonstrates the most stable similarity score over the reasoning steps, indicating a more consistent performance.
* GPT-OSS-20B and Magistral-Small show the most significant fluctuations in similarity, suggesting a less predictable reasoning process.
* DS-R1-Qwen-7B and Qwen3-8B have similar trajectories, with Qwen3-8B generally exhibiting slightly lower similarity scores.
### Interpretation
The chart suggests that the initial stages of reasoning (steps 0-20) are where the models are most aligned with the target concept (represented by the initial high similarity scores). As reasoning progresses, this alignment degrades for all models, but at different rates and with varying degrees of stability. The stability of Claude-3.7-Sonnet could indicate a more robust reasoning process or a better ability to maintain coherence over extended reasoning chains. The volatility of GPT-OSS-20B and Magistral-Small might suggest that these models are more prone to exploring diverse or tangential lines of reasoning, leading to fluctuations in similarity. The differences in trajectories between the models could be attributed to variations in their architectures, training data, or reasoning mechanisms. The metric "Similarity(Cτ, t)" likely measures the alignment of the model's reasoning process (at step t) with a target concept (Cτ). The heuristic nature of the reasoning step (tᵢ) suggests that it's not a direct measure of computational steps but rather a representation of the logical progression of reasoning.