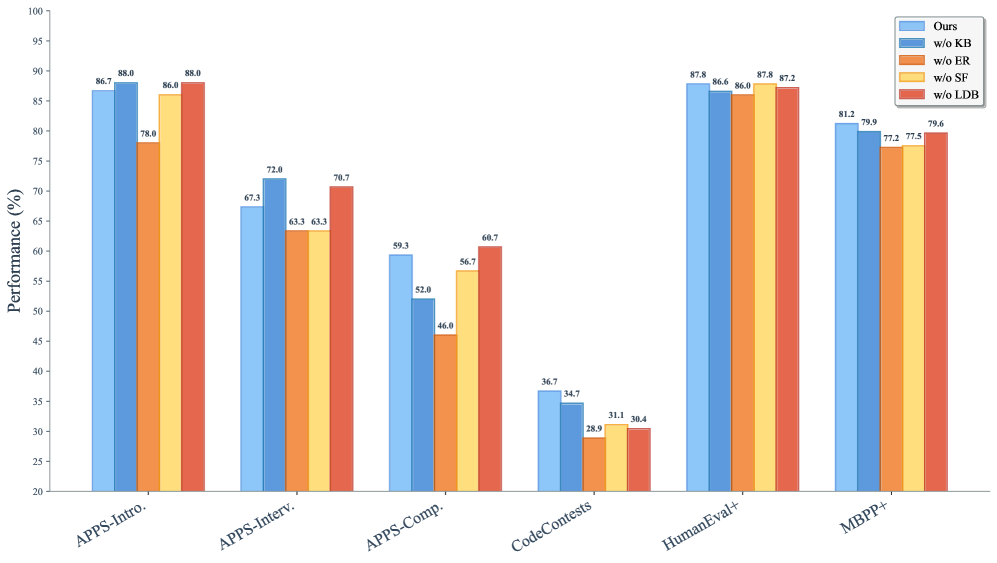
```markdown
## Bar Chart: Performance (%) Across Evaluation Categories
### Overview
The chart compares the performance of five different methods ("Ours", "w/o KB", "w/o ER", "w/o SF", "w/o LDB") across six evaluation categories: APPS-Intro., APPS-Interv., APPS-Comp., CodeContests, HumanEval+, and MBPP+. Performance is measured in percentage (%) on a y-axis from 20 to 100.
### Components/Axes
- **X-axis (Categories)**:
- APPS-Intro.
- APPS-Interv.
- APPS-Comp.
- CodeContests
- HumanEval+
- MBPP+
- **Y-axis (Performance)**:
- Scale: 20–100% (increments of 10)
- Labels: "Performance (%)"
- **Legend**:
- Colors:
- Blue: "Ours"
- Dark Blue: "w/o KB"
- Orange: "w/o ER"
- Yellow: "w/o SF"
- Red: "w/o LDB"
- Position: Top-right corner
### Detailed Analysis
#### APPS-Intro.
- **Ours**: 86.7% (blue)
- **w/o KB**: 88.0% (dark blue)
- **w/o ER**: 78.0% (orange)
- **w/o SF**: 86.0% (yellow)
- **w/o LDB**: 88.0% (red)
#### APPS-Interv.
- **Ours**: 67.3% (blue)
- **w/o KB**: 72.0% (dark blue)
- **w/o ER**: 63.3% (orange)
- **w/o SF**: 63.3% (yellow)
- **w/o LDB**: 70.7% (red)
#### APPS-Comp.
- **Ours**: 59.3% (blue)
- **w/o KB**: 52.0% (dark blue)
- **w/o ER**: 46.0% (orange)
- **w/o SF**: 56.7% (yellow)
- **w/o LDB**: 60.7% (red)
#### CodeContests
- **Ours**: 36.7% (blue)
- **w/o KB**: 34.7% (dark blue)
- **w/o ER**: 28.9% (orange)
- **w/o SF**: 31.1% (yellow)
- **w/o LDB**: 30.4% (red)
#### HumanEval+
- **Ours**: 87.8% (blue)
- **w/o KB**: 86.6% (dark blue)
- **w/o ER**: 86.4% (orange)
- **w/o SF**: 87.8% (yellow)
- **w/o LDB**: 87.2% (red)
#### MBPP+
- **Ours**: 81.2% (blue)
- **w/o KB**: 79.9% (dark blue)
- **w/o ER**: 77.2% (orange)
- **w/o SF**: 77.5% (yellow)
- **w/o LDB**: 79.6% (red)
### Key Observations
1. **Highest Performance**:
- "Ours" achieves the highest scores in **APPS-Intro.** (86.7%) and **HumanEval+** (87.8%).
- "w/o KB" and "w/o LDB" tie for the highest in **APPS-Intro.** (88.0%).
2. **Lowest Performance**:
- **CodeContests** is the weakest category overall, with all methods scoring below 40%.
3. **Component Impact**:
- Removing **KB** improves performance in **APPS-Interv.** (72.0%) and **MBPP+** (79.9%).
- Removing **LDB** boosts results in **APPS-Comp.** (60.7%) and **MBPP+** (79.6%).
- Removing **SF** matches "Ours" in **HumanEval+** (87.8%).
4. **Outliers**:
- **CodeContests** shows drastic drops when components are removed (e.g., "w/o ER" at 28.9%).
### Interpretation
The data suggests that the "Ours" method generally performs robustly across categories