TECHNICAL ASSET FINGERPRINT
8c1358515cf271b457c1b067
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
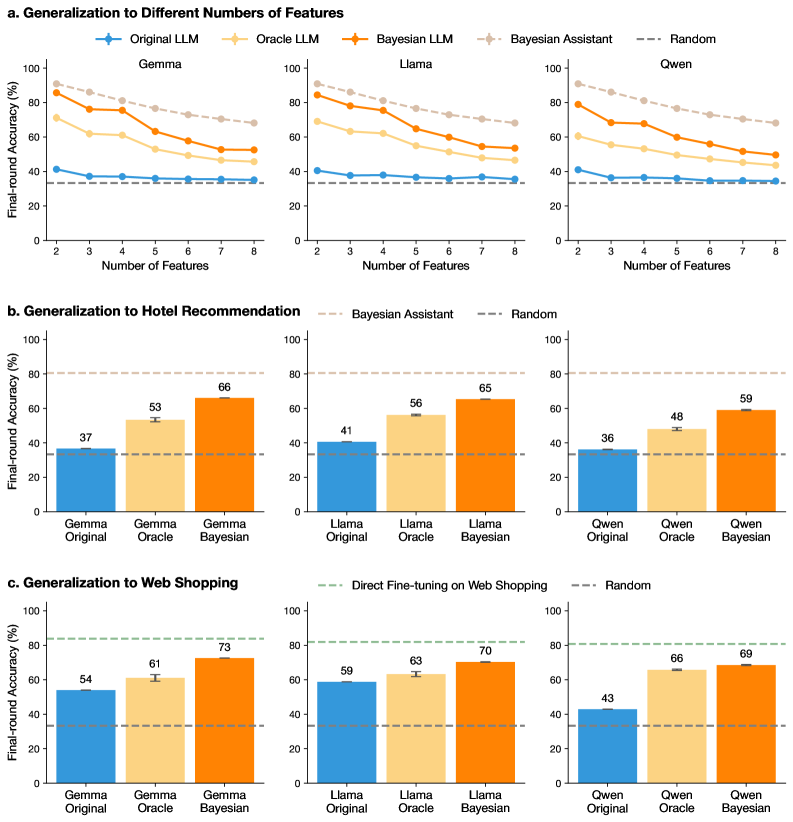
## Chart Type: Performance Comparison of Language Models
### Overview
The image presents a series of bar and line charts comparing the performance of different language models (Gemma, Llama, and Qwen) under various conditions. The charts are organized into three sections: generalization to different numbers of features, generalization to hotel recommendation, and generalization to web shopping. Each section compares the "Original," "Oracle," and "Bayesian" versions of each language model, along with baselines like "Bayesian Assistant" and "Random."
### Components/Axes
**General Components:**
* **Title:** The image is divided into three sections, each with a title: "a. Generalization to Different Numbers of Features," "b. Generalization to Hotel Recommendation," and "c. Generalization to Web Shopping."
* **Y-axis:** All charts share a common Y-axis labeled "Final-round Accuracy (%)" ranging from 0 to 100.
* **Legend:** Located at the top of the image, the legend identifies the different language model versions and baselines using color-coded lines and bars:
* Original LLM (Blue)
* Oracle LLM (Light Orange)
* Bayesian LLM (Orange)
* Bayesian Assistant (Light Gray, dashed line)
* Random (Dark Gray, dashed line)
**Section a: Generalization to Different Numbers of Features**
* **X-axis:** Labeled "Number of Features," ranging from 2 to 8.
* **Subplots:** Three subplots, one for each language model: Gemma, Llama, and Qwen.
* **Data Series:** Each subplot contains line plots for "Original LLM," "Oracle LLM," "Bayesian LLM," "Bayesian Assistant," and "Random."
**Section b: Generalization to Hotel Recommendation**
* **X-axis:** Categorical, with three categories for each language model: "Original," "Oracle," and "Bayesian."
* **Subplots:** Three subplots, one for each language model: Gemma, Llama, and Qwen.
* **Data Series:** Each subplot contains bar plots for "Original," "Oracle," and "Bayesian" versions of the language model.
**Section c: Generalization to Web Shopping**
* **X-axis:** Categorical, with three categories for each language model: "Original," "Oracle," and "Bayesian."
* **Subplots:** Three subplots, one for each language model: Gemma, Llama, and Qwen.
* **Data Series:** Each subplot contains bar plots for "Original," "Oracle," and "Bayesian" versions of the language model.
### Detailed Analysis
**Section a: Generalization to Different Numbers of Features**
* **Gemma:**
* Original LLM (Blue): Relatively flat line around 37% accuracy.
* Oracle LLM (Light Orange): Decreases from approximately 90% at 2 features to 55% at 8 features.
* Bayesian LLM (Orange): Decreases from approximately 95% at 2 features to 60% at 8 features.
* Bayesian Assistant (Light Gray, dashed line): Flat line around 80% accuracy.
* Random (Dark Gray, dashed line): Flat line around 37% accuracy.
* **Llama:**
* Original LLM (Blue): Relatively flat line around 41% accuracy.
* Oracle LLM (Light Orange): Decreases from approximately 80% at 2 features to 50% at 8 features.
* Bayesian LLM (Orange): Decreases from approximately 90% at 2 features to 55% at 8 features.
* Bayesian Assistant (Light Gray, dashed line): Flat line around 80% accuracy.
* Random (Dark Gray, dashed line): Flat line around 37% accuracy.
* **Qwen:**
* Original LLM (Blue): Relatively flat line around 36% accuracy.
* Oracle LLM (Light Orange): Decreases from approximately 75% at 2 features to 45% at 8 features.
* Bayesian LLM (Orange): Decreases from approximately 85% at 2 features to 50% at 8 features.
* Bayesian Assistant (Light Gray, dashed line): Flat line around 80% accuracy.
* Random (Dark Gray, dashed line): Flat line around 37% accuracy.
**Section b: Generalization to Hotel Recommendation**
* **Gemma:**
* Original (Blue): 37% accuracy.
* Oracle (Light Orange): 53% accuracy.
* Bayesian (Orange): 66% accuracy.
* **Llama:**
* Original (Blue): 41% accuracy.
* Oracle (Light Orange): 56% accuracy.
* Bayesian (Orange): 65% accuracy.
* **Qwen:**
* Original (Blue): 36% accuracy.
* Oracle (Light Orange): 48% accuracy.
* Bayesian (Orange): 59% accuracy.
**Section c: Generalization to Web Shopping**
* **Gemma:**
* Original (Blue): 54% accuracy.
* Oracle (Light Orange): 61% accuracy.
* Bayesian (Orange): 73% accuracy.
* **Llama:**
* Original (Blue): 59% accuracy.
* Oracle (Light Orange): 63% accuracy.
* Bayesian (Orange): 70% accuracy.
* **Qwen:**
* Original (Blue): 43% accuracy.
* Oracle (Light Orange): 66% accuracy.
* Bayesian (Orange): 69% accuracy.
### Key Observations
* In the "Generalization to Different Numbers of Features" section, the "Original LLM" models maintain a relatively constant accuracy regardless of the number of features, while the "Oracle LLM" and "Bayesian LLM" models show a decreasing trend in accuracy as the number of features increases.
* In both the "Hotel Recommendation" and "Web Shopping" sections, the "Bayesian" versions of each language model consistently outperform the "Original" and "Oracle" versions.
* The "Bayesian Assistant" baseline in the "Generalization to Different Numbers of Features" section consistently achieves around 80% accuracy.
* The "Random" baseline consistently achieves around 37% accuracy across all sections.
* The "Direct Fine-tuning on Web Shopping" baseline in the "Web Shopping" section achieves around 80% accuracy.
### Interpretation
The data suggests that the "Oracle" and "Bayesian" versions of the language models are more sensitive to the number of features, as their accuracy decreases as the number of features increases. This could indicate that these models are more prone to overfitting or that they require more data to generalize effectively with a larger number of features.
The "Bayesian" versions of the language models consistently outperform the "Original" and "Oracle" versions in the "Hotel Recommendation" and "Web Shopping" tasks, suggesting that the Bayesian approach is more effective for these specific tasks.
The baselines provide a point of reference for evaluating the performance of the language models. The "Random" baseline indicates the expected accuracy of a random guess, while the "Bayesian Assistant" and "Direct Fine-tuning on Web Shopping" baselines represent the performance of alternative approaches.
The error bars on the bar charts indicate the variability in the accuracy of the models. The error bars are relatively small, suggesting that the results are consistent and reliable.
DECODING INTELLIGENCE...