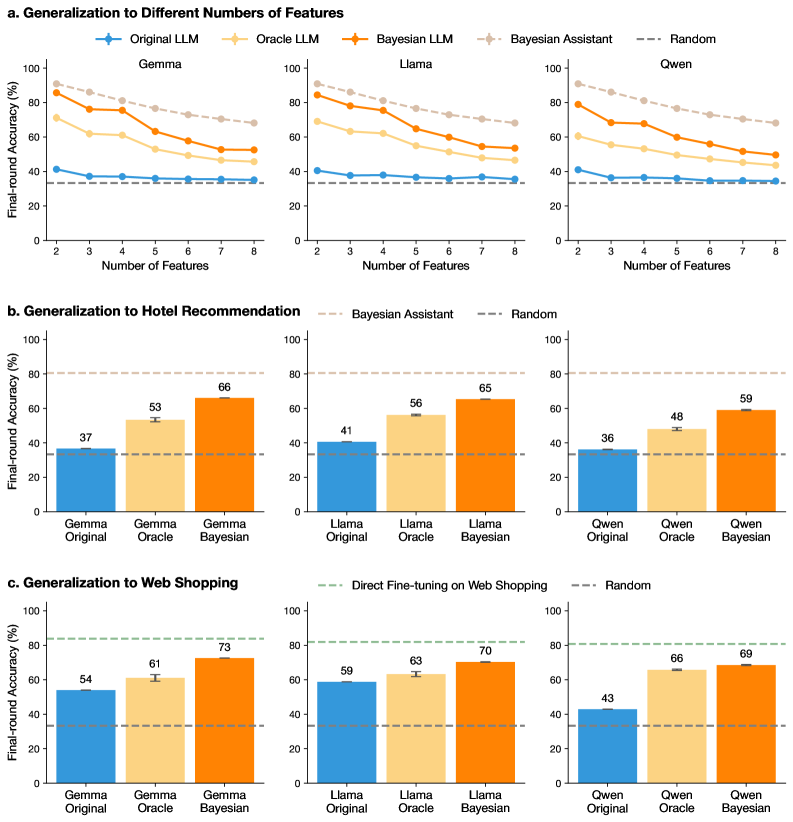
\n
## Charts: Generalization Performance of LLMs
### Overview
The image presents three sets of charts comparing the performance of several Large Language Models (LLMs) – Gemma, Llama, Owen, and a Random baseline – across different generalization tasks. The first set (a) examines performance as a function of the number of features used. The second (b) focuses on generalization to Hotel Recommendation, and the third (c) on Web Shopping. All charts use Final-round Accuracy (%) as the y-axis. Error bars are present in the bar charts.
### Components/Axes
* **X-axis (Charts a):** Number of Features (ranging from 2 to 8).
* **Y-axis (All Charts):** Final-round Accuracy (%) (ranging from 0 to 100).
* **Legends (Chart a):**
* Original LLM (Red Line)
* Oracle LLM (Blue Line)
* Bayesian Assistant (Purple Line)
* Random (Gray Dashed Line)
* **X-axis Labels (Charts b & c):** Gemma Original, Gemma Oracle, Gemma Bayesian, Llama Original, Llama Oracle, Llama Bayesian, Owen Original, Owen Oracle, Owen Bayesian.
* **Legends (Charts b & c):**
* Bayesian Assistant (Charts b & c)
* Random (Charts b & c)
* Direct Fine-tuning on Web Shopping (Chart c)
### Detailed Analysis or Content Details
**a. Generalization to Different Numbers of Features**
* **Original LLM (Red):** Starts at approximately 70% accuracy with 2 features, dips to around 50% with 4 features, then rises to approximately 75% with 8 features.
* **Oracle LLM (Blue):** Starts at approximately 60% accuracy with 2 features, decreases to around 40% with 5 features, and then plateaus around 45% with 8 features.
* **Bayesian Assistant (Purple):** Starts at approximately 50% accuracy with 2 features, rises to a peak of around 70% with 6 features, and then declines to approximately 60% with 8 features.
* **Random (Gray Dashed):** Remains relatively constant around 20% accuracy across all feature numbers.
**b. Generalization to Hotel Recommendation**
* **Gemma Original:** Approximately 37% accuracy.
* **Gemma Oracle:** Approximately 53% accuracy.
* **Gemma Bayesian:** Approximately 66% accuracy.
* **Llama Original:** Approximately 41% accuracy.
* **Llama Oracle:** Approximately 56% accuracy.
* **Llama Bayesian:** Approximately 65% accuracy.
* **Owen Original:** Approximately 36% accuracy.
* **Owen Oracle:** Approximately 48% accuracy.
* **Owen Bayesian:** Approximately 59% accuracy.
**c. Generalization to Web Shopping**
* **Gemma Original:** Approximately 54% accuracy.
* **Gemma Oracle:** Approximately 61% accuracy.
* **Gemma Bayesian:** Approximately 73% accuracy.
* **Llama Original:** Approximately 59% accuracy.
* **Llama Oracle:** Approximately 63% accuracy.
* **Llama Bayesian:** Approximately 70% accuracy.
* **Owen Original:** Approximately 43% accuracy.
* **Owen Oracle:** Approximately 66% accuracy.
* **Owen Bayesian:** Approximately 69% accuracy.
### Key Observations
* The Bayesian Assistant consistently outperforms the Original and Oracle LLMs across all tasks.
* Performance generally increases with the addition of features (Chart a), but the relationship is not always linear. Some models show a dip in performance at intermediate feature counts.
* The Random baseline consistently performs poorly, indicating that the LLMs are learning something beyond chance.
* The Oracle LLM generally performs better than the Original LLM, but not as well as the Bayesian Assistant.
* Gemma Bayesian consistently achieves the highest accuracy in the Hotel Recommendation and Web Shopping tasks.
### Interpretation
The data suggests that the Bayesian Assistant approach is the most effective for generalization in these tasks. The improvement over the Original and Oracle LLMs indicates that the Bayesian method is better at incorporating prior knowledge and handling uncertainty. The varying performance with different numbers of features (Chart a) suggests that there is an optimal level of complexity for each model and task. The consistent poor performance of the Random baseline validates the effectiveness of the LLMs. The fact that the Oracle LLM performs better than the Original LLM suggests that providing access to additional information (the "oracle") can improve performance, but the Bayesian Assistant is still superior. The differences in performance between the models on different tasks (Hotel Recommendation vs. Web Shopping) suggest that the optimal model architecture and training data may vary depending on the specific application. The error bars in charts b and c indicate the variability of the results, and further statistical analysis would be needed to determine the significance of the observed differences.