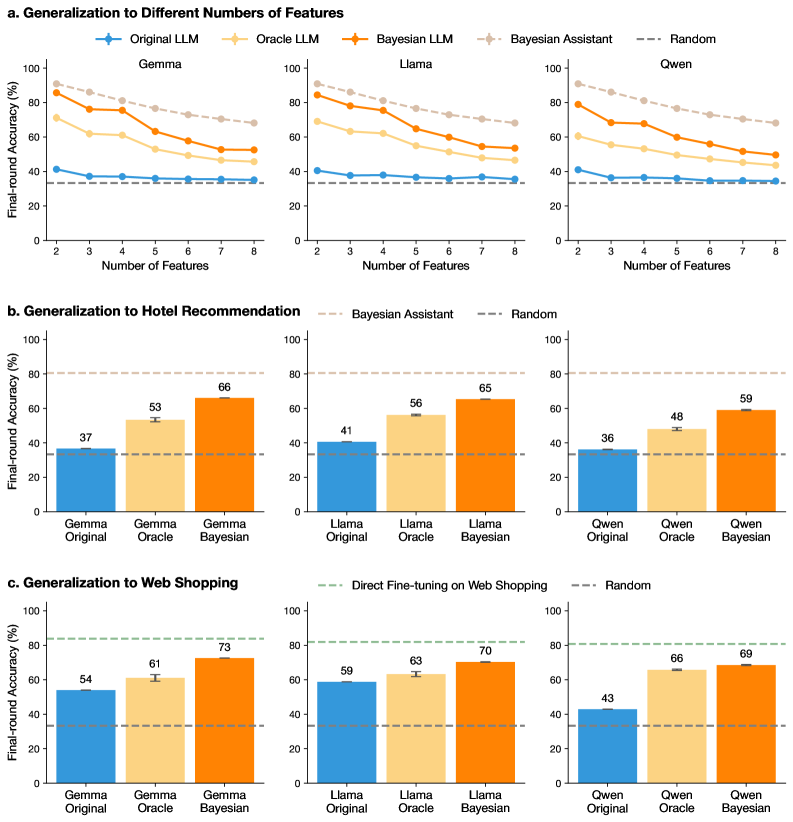
## Line Graphs: Generalization to Different Numbers of Features
### Overview
Three line graphs compare the performance of machine learning models (Gemma, Llama, Owen) across tasks (Generalization, Hotel Recommendation, Web Shopping) as the number of features increases. Models include Original LLM, Oracle LLM, Bayesian LLM, Bayesian Assistant, and Random baseline.
### Components/Axes
- **X-axis**: Number of Features (2–8)
- **Y-axis**: Final-round Accuracy (%)
- **Legends**:
- Blue: Original LLM
- Yellow: Oracle LLM
- Orange: Bayesian LLM
- Pink: Bayesian Assistant
- Dashed Gray: Random
### Detailed Analysis
1. **Gemma (Top-Left Graph)**
- **Trend**: All models decline in accuracy as features increase. Bayesian LLM (orange) starts highest (~85%) and declines slowly, while Original LLM (blue) starts at ~40% and plateaus.
- **Data Points**:
- 2 features: Bayesian LLM 85%, Oracle LLM 70%, Original LLM 40%
- 8 features: Bayesian LLM 60%, Oracle LLM 50%, Original LLM 35%
2. **Llama (Top-Center Graph)**
- **Trend**: Similar decline, but Bayesian LLM maintains higher accuracy (~80% at 2 features vs. 60% for Original LLM).
- **Data Points**:
- 2 features: Bayesian LLM 80%, Oracle LLM 65%, Original LLM 38%
- 8 features: Bayesian LLM 65%, Oracle LLM 55%, Original LLM 37%
3. **Owen (Top-Right Graph)**
- **Trend**: Bayesian LLM starts at ~85% (2 features) and declines to ~60% (8 features). Original LLM starts at ~40% and drops to ~30%.
- **Data Points**:
- 2 features: Bayesian LLM 85%, Oracle LLM 70%, Original LLM 40%
- 8 features: Bayesian LLM 60%, Oracle LLM 50%, Original LLM 30%
### Key Observations
- Bayesian models consistently outperform others across all tasks and feature counts.
- Oracle LLM performs better than Original LLM but lags behind Bayesian models.
- Random baseline remains flat (~30–40%) across all tasks.
### Interpretation
Bayesian models demonstrate superior generalization, maintaining higher accuracy even with increased feature complexity. Oracle models approximate Bayesian performance but with a steeper decline, suggesting they may overfit or lack adaptability. The Random baseline’s flat performance indicates that all models outperform chance.
---
## Bar Charts: Generalization to Hotel Recommendation & Web Shopping
### Overview
Bar charts compare model performance (Gemma, Llama, Owen) in specific tasks (Hotel Recommendation, Web Shopping) using Original, Oracle, and Bayesian variants.
### Components/Axes
- **X-axis**: Model Variants (Original, Oracle, Bayesian)
- **Y-axis**: Final-round Accuracy (%)
- **Legends**:
- Blue: Original
- Yellow: Oracle
- Orange: Bayesian
### Detailed Analysis
1. **Hotel Recommendation (Bottom-Left Graph)**
- **Trend**: Bayesian models dominate:
- Gemma Bayesian: 66%
- Llama Bayesian: 65%
- Owen Bayesian: 59%
- **Original/Oracle**:
- Gemma Original: 37%, Oracle: 53%
- Llama Original: 41%, Oracle: 56%
- Owen Original: 36%, Oracle: 48%
2. **Web Shopping (Bottom-Center Graph)**
- **Trend**: Bayesian models again lead:
- Gemma Bayesian: 73%
- Llama Bayesian: 70%
- Owen Bayesian: 69%
- **Original/Oracle**:
- Gemma Original: 54%, Oracle: 61%
- Llama Original: 59%, Oracle: 63%
- Owen Original: 43%, Oracle: 66%
### Key Observations
- Bayesian models achieve **20–30% higher accuracy** than Oracle models in Web Shopping.
- In Hotel Recommendation, Bayesian models outperform Oracle by **10–15%**.
- Original models perform poorly compared to Oracle and Bayesian variants.
### Interpretation
Bayesian models excel in domain-specific tasks (Hotel Recommendation, Web Shopping), likely due to their probabilistic reasoning. Oracle models act as strong baselines but lack the adaptability of Bayesian approaches. The gap between Original and Oracle models highlights the importance of model architecture over raw data.
---
## General Trends Across All Charts
1. **Bayesian Superiority**: Bayesian models consistently outperform others, suggesting their probabilistic framework enhances generalization.
2. **Feature Complexity Trade-off**: Accuracy declines as features increase, but Bayesian models degrade slower, indicating robustness.
3. **Oracle as Midpoint**: Oracle models bridge the gap between Original and Bayesian but fail to match Bayesian adaptability.
4. **Random Baseline**: All models outperform chance (30–40%), validating their utility.
## Conclusion
Bayesian models demonstrate the best generalization across tasks and feature complexity, making them ideal for dynamic, real-world applications. Oracle models serve as strong benchmarks, while Original models require significant improvement for practical use. The data underscores the value of probabilistic reasoning in machine learning systems.