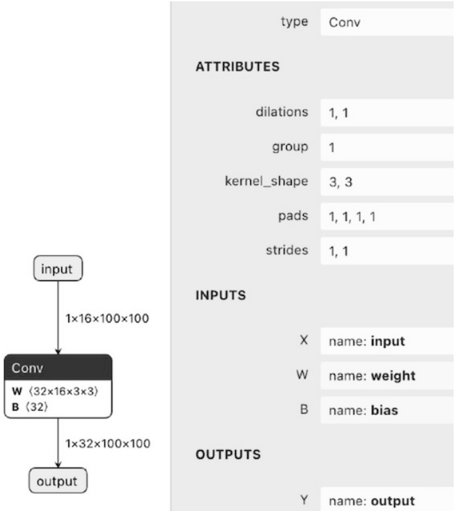
## [Diagram Type]: Convolutional Neural Network Layer Specification
### Overview
The image presents a technical specification and a visual flow diagram for a Convolutional (Conv) layer within a neural network architecture. The left side of the image illustrates the data flow through the layer, including tensor shapes, while the right side provides a detailed configuration panel listing the layer's attributes, inputs, and outputs.
### Components/Structure
The image is divided into two primary regions:
**1. Left Region: Flow Diagram**
A vertical flowchart representing the transformation of data.
* **Top Node:** "input"
* **Flow Arrow 1:** Labeled "1x16x100x100" (representing the input tensor shape: Batch x Channels x Height x Width).
* **Middle Node:** A rectangular block labeled "Conv" (with a dark header).
* Inside the block:
* "W {32x16x3x3}" (Weight tensor shape)
* "B {32}" (Bias tensor shape)
* **Flow Arrow 2:** Labeled "1x32x100x100" (representing the output tensor shape).
* **Bottom Node:** "output"
**2. Right Region: Parameter Panel**
A structured list of metadata and configuration settings.
* **Header:** "type" -> "Conv"
* **Section: ATTRIBUTES**
* "dilations": "1, 1"
* "group": "1"
* "kernel_shape": "3, 3"
* "pads": "1, 1, 1, 1"
* "strides": "1, 1"
* **Section: INPUTS**
* "X": "name: input"
* "W": "name: weight"
* "B": "name: bias"
* **Section: OUTPUTS**
* "Y": "name: output"
### Detailed Analysis
The diagram describes a standard 2D convolution operation with the following technical specifications:
* **Input Tensor:** 1 batch, 16 channels, 100x100 spatial resolution.
* **Weight Tensor (W):** 32 output channels, 16 input channels, 3x3 kernel size.
* **Bias Tensor (B):** 32 values (one per output channel).
* **Output Tensor:** 1 batch, 32 channels, 100x100 spatial resolution.
* **Configuration Attributes:**
* **Kernel Shape:** 3x3.
* **Strides:** 1, 1 (The filter moves one pixel at a time).
* **Pads:** 1, 1, 1, 1 (Padding of 1 pixel on all four sides: top, bottom, left, right).
* **Dilations:** 1, 1 (Standard convolution, no gaps in the kernel).
* **Group:** 1 (Standard convolution, not depthwise or grouped).
### Key Observations
* **Spatial Preservation:** The input spatial dimensions (100x100) are identical to the output spatial dimensions (100x100). This is achieved because the 3x3 kernel combined with a padding of 1 on all sides results in "same" padding, which preserves the input size.
* **Channel Expansion:** The layer transforms the feature map from 16 channels to 32 channels.
* **Weight Shape Logic:** The weight tensor shape `32x16x3x3` follows the standard convention of `[Output_Channels, Input_Channels, Kernel_Height, Kernel_Width]`.
### Interpretation
This diagram represents a standard "Same" Convolution layer.
The data demonstrates a feature extraction or transformation step where the network increases the depth of the feature map (from 16 to 32) while maintaining the spatial resolution of the input. The use of `pads: 1, 1, 1, 1` is critical here; without this padding, a 3x3 kernel would reduce the spatial dimensions from 100x100 to 98x98. By explicitly padding, the architect ensures that the spatial information remains consistent, which is a common design pattern in deep residual networks or U-Net architectures to facilitate element-wise addition or concatenation later in the pipeline. The `group: 1` setting confirms this is a dense, fully-connected convolution across all input channels.