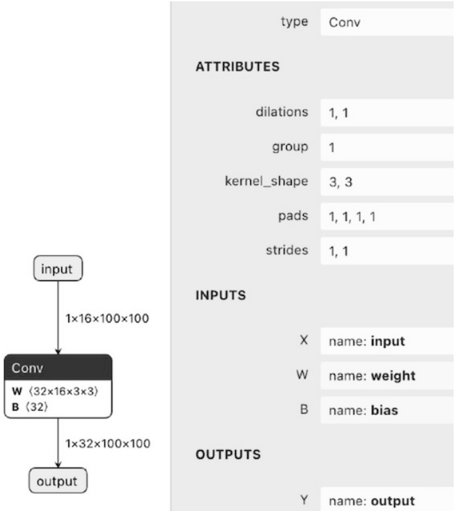
## Diagram: Convolutional Neural Network Layer (Conv)
### Overview
The image depicts a technical diagram of a convolutional neural network (CNN) layer, specifically a "Conv" layer. It includes a flowchart on the left and a structured table on the right. The flowchart illustrates the flow of data through the layer, while the table details the layer's attributes, inputs, and outputs.
### Components/Axes
#### Left Diagram (Flowchart):
- **Input**: Labeled as "input" with dimensions `1x16x100x100`.
- **Conv Layer**: Contains parameters:
- `W (32x16x3x3)` (weights)
- `B (32)` (bias)
- **Output**: Labeled as "output" with dimensions `1x32x100x100`.
- **Arrows**: Indicate the flow from input → Conv layer → output.
#### Right Table (Attributes/Inputs/Outputs):
- **Attributes**:
- `dilations`: `1, 1`
- `group`: `1`
- `kernel_shape`: `3, 3`
- `pads`: `1, 1, 1, 1`
- `strides`: `1, 1`
- **Inputs**:
- `X` (name: "input")
- `W` (name: "weight")
- `B` (name: "bias")
- **Outputs**:
- `Y` (name: "output")
### Detailed Analysis
- **Input Dimensions**: The input tensor has a shape of `1x16x100x100`, indicating a single-channel (grayscale) image with height and width of 100.
- **Conv Layer Parameters**:
- **Kernel Shape**: `3x3` (3x3 spatial kernel).
- **Pads**: `1, 1, 1, 1` (padding added to all sides of the input).
- **Strides**: `1, 1` (step size for sliding the kernel).
- **Dilations**: `1, 1` (no dilation, standard convolution).
- **Group**: `1` (single group, no grouped convolution).
- **Output Dimensions**: The output tensor has a shape of `1x32x100x100`, indicating 32 output channels (feature maps) with the same spatial dimensions as the input.
- **Inputs/Outputs**:
- `X` (input) is the original data.
- `W` (weights) and `B` (bias) are learnable parameters.
- `Y` (output) is the result of the convolution operation.
### Key Observations
- The Conv layer preserves spatial dimensions (`100x100`) due to padding (`1` on all sides) and stride (`1`).
- The number of output channels (`32`) is determined by the weight tensor `W` (32x16x3x3), where the first dimension (32) corresponds to the number of filters.
- The `kernel_shape` of `3x3` suggests a standard convolution for edge detection or feature extraction.
- The `group=1` indicates no grouped convolution, meaning all input channels are connected to all output channels.
### Interpretation
This diagram illustrates a standard 2D convolutional layer in a CNN. The input is processed with a `3x3` kernel, padded to maintain spatial dimensions, and transformed into 32 feature maps. The parameters (`dilations`, `group`, `kernel_shape`, `pads`, `strides`) define how the kernel interacts with the input. The output retains the same spatial resolution as the input but increases the number of channels, enabling the network to learn hierarchical features. The table on the right provides a structured summary of the layer's configuration, critical for implementation or debugging.
No numerical trends or anomalies are present, as this is a static diagram of a layer configuration rather than a dynamic dataset.