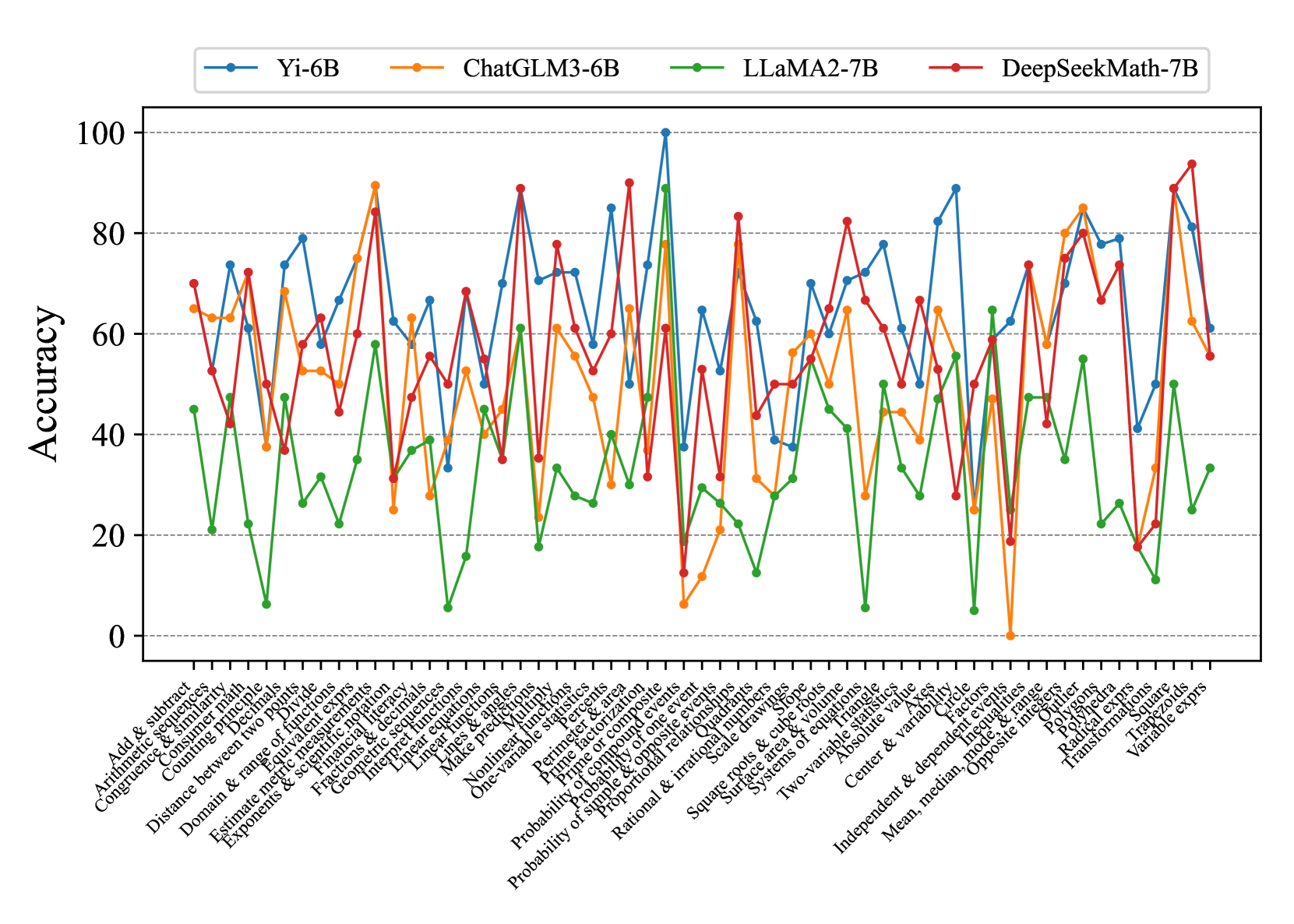
\n
## Line Chart: Model Accuracy on Math Problems
### Overview
This line chart compares the accuracy of four different language models – Yi-6B, ChatGLM3-6B, LLaMA2-7B, and DeepSeekMath-7B – across a range of mathematical problem types. The x-axis represents the problem type, and the y-axis represents the accuracy, ranging from 0 to 100. The chart displays the performance of each model as a line, allowing for a visual comparison of their strengths and weaknesses.
### Components/Axes
* **X-axis Title:** Problem Type (Categorical)
* **Y-axis Title:** Accuracy (Numerical, 0-100)
* **Legend:** Located at the top-center of the chart.
* Yi-6B (Blue Line)
* ChatGLM3-6B (Orange Line)
* LLaMA2-7B (Green Line)
* DeepSeekMath-7B (Black Line)
* **Problem Types (X-axis labels):**
1. Arithmetic & significant figures
2. Add & subtract
3. Arithmetic & similar triangles
4. Congruence
5. Combining like terms
6. Distance between two points
7. Domain & range
8. Estimate medical measurements
9. Exponents & radicals
10. Fractional exponents
11. Integer exponents
12. Linear functions
13. Make inequalities
14. Nonlinear multiple choice
15. One variable equations
16. Perimeter & area
17. Prime factorization
18. Probability of a single event
19. Probability of compound events
20. Probability of independent events
21. Rational & irrational numbers
22. Square roots & cube roots
23. Systems of equations
24. Two-variable equations
25. Absolute value
26. Center & variability
27. Independent & dependent variables
28. Mean, median, mode
29. Polynomials
30. Transformations
31. Variable exponents
### Detailed Analysis
Here's a breakdown of each model's performance, based on the visual trends and approximate data points:
* **Yi-6B (Blue Line):** This line generally fluctuates between 20 and 80 accuracy. It shows a peak of approximately 85 accuracy around the "Linear functions" problem type. It dips to around 10-20 accuracy for "Rational & irrational numbers" and "Square roots & cube roots". The line exhibits significant volatility across different problem types.
* **ChatGLM3-6B (Orange Line):** This model demonstrates the lowest overall accuracy, consistently staying below 40. It has a slight peak around 35-40 for "Arithmetic & significant figures" and "Add & subtract". It reaches its lowest point, near 0, for "Square roots & cube roots". The line is relatively flat, indicating consistent low performance.
* **LLaMA2-7B (Green Line):** This model shows a moderate level of accuracy, generally between 30 and 70. It has a peak of approximately 70 accuracy around "Polynomials". It dips to around 20-30 for "Rational & irrational numbers" and "Square roots & cube roots". The line is more stable than Yi-6B, but less consistently high-performing than DeepSeekMath-7B.
* **DeepSeekMath-7B (Black Line):** This model consistently achieves the highest accuracy, frequently exceeding 80. It reaches a peak of approximately 90 accuracy around "Linear functions" and "Polynomials". It dips to around 50-60 for "Square roots & cube roots" and "Variable exponents". The line is generally smooth, indicating robust performance across most problem types.
### Key Observations
* DeepSeekMath-7B consistently outperforms the other models across almost all problem types.
* ChatGLM3-6B consistently underperforms, exhibiting the lowest accuracy.
* All models struggle with "Rational & irrational numbers" and "Square roots & cube roots", showing a significant drop in accuracy for these problem types.
* Yi-6B and LLaMA2-7B show more variability in their performance, with larger fluctuations in accuracy depending on the problem type.
* "Linear functions" and "Polynomials" appear to be the easiest problem types for the models, as they consistently achieve higher accuracy on these.
### Interpretation
The data suggests that DeepSeekMath-7B is the most capable model for solving a wide range of mathematical problems, likely due to its specialized training or architecture. ChatGLM3-6B appears to be the least effective, potentially indicating a lack of mathematical reasoning capabilities. The consistent struggles with "Rational & irrational numbers" and "Square roots & cube roots" across all models suggest these concepts are particularly challenging for language models, possibly due to the need for precise numerical manipulation and understanding of abstract mathematical principles. The variability in Yi-6B and LLaMA2-7B's performance highlights the importance of problem-specific expertise; these models may excel in certain areas but struggle in others. The chart demonstrates a clear hierarchy of performance among the models, with DeepSeekMath-7B setting a high benchmark for mathematical problem-solving. The differences in performance could be attributed to differences in model size, training data, and architectural choices. Further investigation into the training data and model architectures could provide insights into the reasons for these performance disparities.