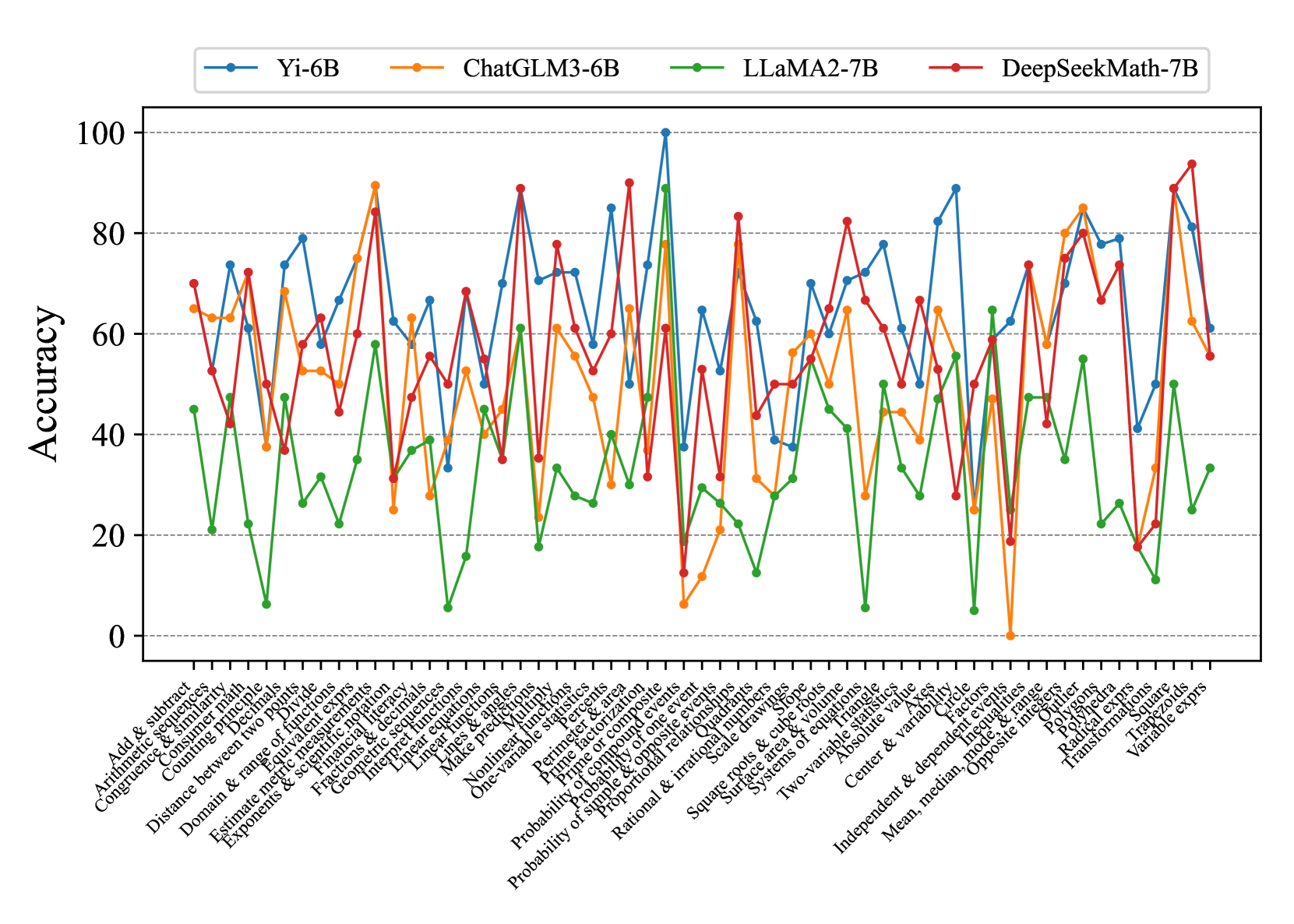
## Line Chart: ModelAccuracy Across Math Topics
### Overview
The chart compares the accuracy of four AI models (Yi-6B, ChatGLM3-6B, LLaMA2-7B, DeepSeekMath-7B) across 30+ math topics. Accuracy is measured on a 0–100% scale, with each model represented by a distinct colored line. The x-axis lists math topics, while the y-axis shows accuracy percentages.
### Components/Axes
- **Legend**: Top-left corner, with four entries:
- **Yi-6B** (blue line)
- **ChatGLM3-6B** (orange line)
- **LLaMA2-7B** (green line)
- **DeepSeekMath-7B** (red line)
- **X-axis**: Labeled "Math Topics," listing 30+ categories (e.g., "Add & subtract," "Probability & statistics," "Geometry & range").
- **Y-axis**: Labeled "Accuracy," with ticks at 0, 20, 40, 60, 80, 100.
### Detailed Analysis
1. **Yi-6B (Blue)**:
- Peaks at ~95% in "Probability & statistics" and "Geometry & range."
- Dips below 40% in "Linear equations" and "Nonlinear functions."
- Average accuracy: ~65–75% across most topics.
2. **ChatGLM3-6B (Orange)**:
- Strong performance in "Exponents & scientific notation" (~85%).
- Struggles in "Linear equations" (~30%) and "Systems of equations" (~40%).
- Average accuracy: ~55–70%.
3. **LLaMA2-7B (Green)**:
- Consistently mid-range (40–60%) across most topics.
- Peaks at ~70% in "Probability & statistics" and "Geometry & range."
- Lowest accuracy: ~10% in "Linear equations."
4. **DeepSeekMath-7B (Red)**:
- Highest overall accuracy (~85–95%) in "Probability & statistics," "Geometry & range," and "Exponents & scientific notation."
- Dips below 40% in "Linear equations" and "Nonlinear functions."
- Average accuracy: ~70–85%.
### Key Observations
- **Outliers**:
- LLaMA2-7B (green) has the lowest accuracy in "Linear equations" (~10%).
- DeepSeekMath-7B (red) achieves the highest accuracy in "Probability & statistics" (~95%).
- **Trends**:
- Yi-6B and DeepSeekMath-7B show the most variability, with sharp peaks and troughs.
- ChatGLM3-6B and LLaMA2-7B exhibit more stable but lower performance.
### Interpretation
The data highlights model-specific strengths and weaknesses:
- **DeepSeekMath-7B** excels in advanced topics like probability and geometry, suggesting robust training in these areas.
- **LLaMA2-7B** underperforms in linear equations, indicating potential gaps in foundational math training.
- **Yi-6B** and **ChatGLM3-6B** show mixed results, with Yi-6B performing better in high-variability topics and ChatGLM3-6B struggling in linear systems.
The chart underscores the importance of model selection based on the target math domain. For example, DeepSeekMath-7B would be preferable for probability tasks, while LLaMA2-7B might be avoided for linear equations.