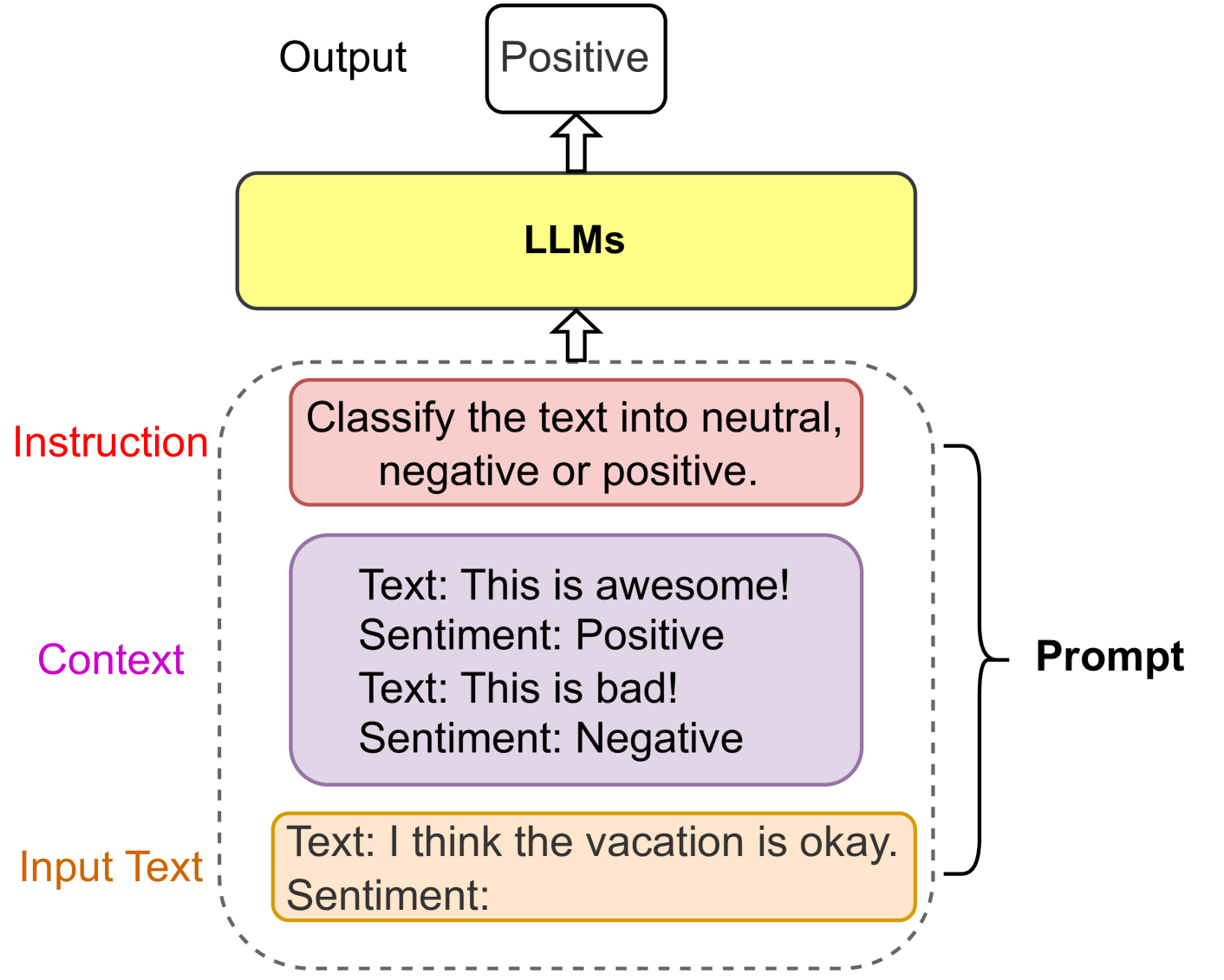
## Diagram: LLM Sentiment Analysis
### Overview
The image illustrates a diagram of a Large Language Model (LLM) performing sentiment analysis. It shows the input prompt, the LLM processing, and the output sentiment. The prompt consists of an instruction, context examples, and the input text to be analyzed.
### Components/Axes
* **Output:** Located at the top of the diagram. The output is "Positive" within a white rounded rectangle.
* **LLMs:** A yellow rounded rectangle representing the Large Language Models.
* **Instruction:** A red label on the left side, pointing to a light red rounded rectangle containing the instruction: "Classify the text into neutral, negative or positive."
* **Context:** A purple label on the left side, pointing to a light purple rounded rectangle containing example texts and their sentiments:
* "Text: This is awesome! Sentiment: Positive"
* "Text: This is bad! Sentiment: Negative"
* **Input Text:** An orange label on the left side, pointing to a light orange rounded rectangle containing the input text: "Text: I think the vacation is okay. Sentiment:"
* **Prompt:** A black label on the right side, indicating that the instruction, context, and input text together form the prompt. The prompt is enclosed by a dashed grey line.
### Detailed Analysis or ### Content Details
The diagram shows the flow of information:
1. The prompt, consisting of the instruction, context, and input text, is fed into the LLM.
2. The LLM processes the input and generates an output sentiment.
3. The output sentiment in this case is "Positive".
### Key Observations
* The diagram illustrates a typical prompt-based approach for sentiment analysis using LLMs.
* The prompt includes an instruction, examples of text and sentiment pairs (context), and the input text for which the sentiment needs to be determined.
* The LLM correctly identifies the sentiment of "I think the vacation is okay" as "Positive".
### Interpretation
The diagram demonstrates how LLMs can be used for sentiment analysis by providing a clear instruction, relevant context, and the input text. The LLM uses the provided information to classify the sentiment of the input text. The example shows a successful sentiment classification, indicating the LLM's ability to understand and analyze text.