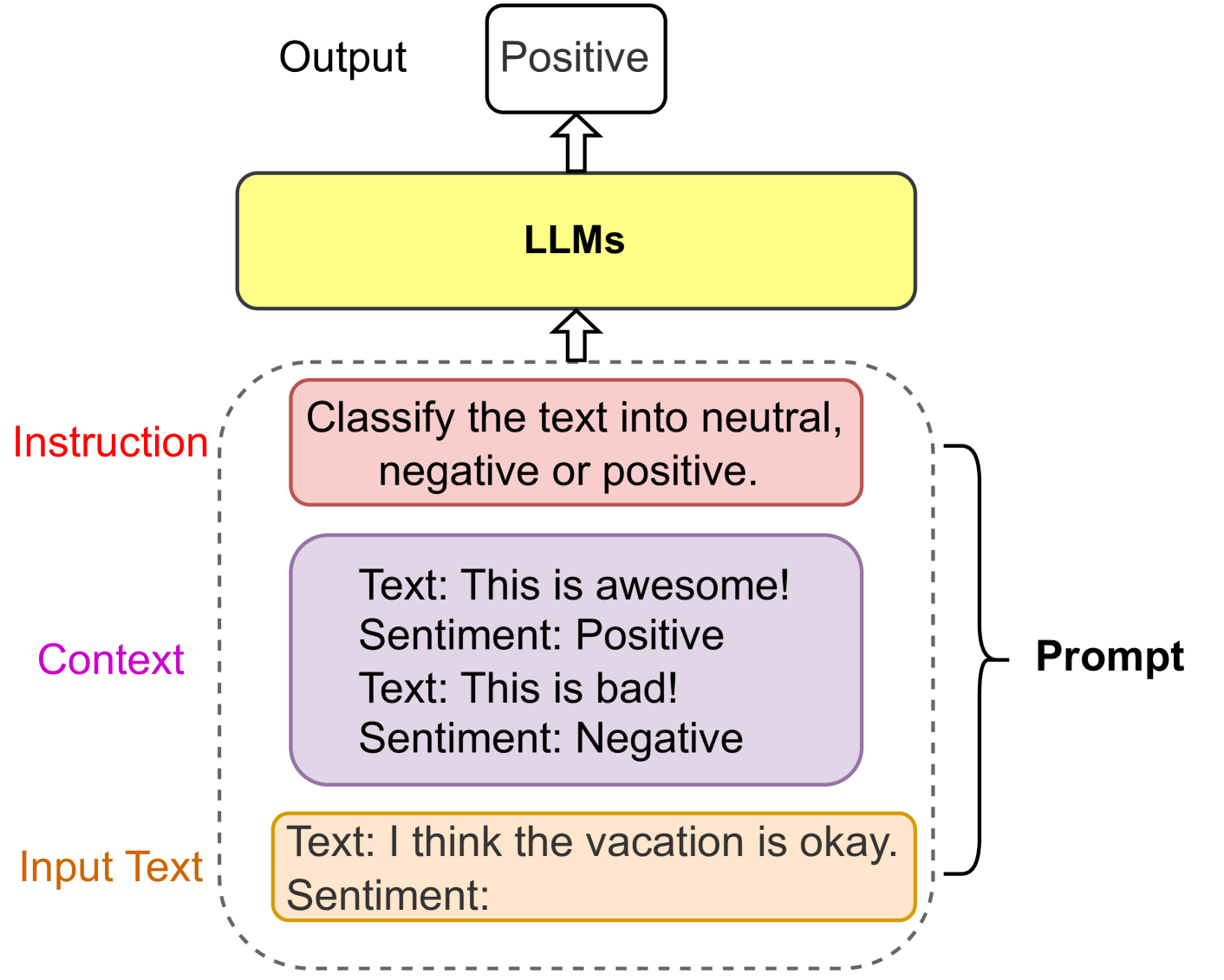
## Diagram: LLM Sentiment Classification Workflow
### Overview
This diagram illustrates the process flow of a Large Language Model (LLM) classifying text sentiment. It shows how input text is processed through a structured prompt to generate a sentiment output (positive/negative/neutral).
### Components/Axes
1. **Output**:
- Labeled "Positive" (white box at top).
2. **LLMs**:
- Central yellow rectangle labeled "LLMs" (Large Language Models).
3. **Dashed Box**:
- Contains three labeled sections:
- **Instruction** (red text): "Classify the text into neutral, negative or positive."
- **Context** (purple text):
- Example 1: "Text: This is awesome! Sentiment: Positive"
- Example 2: "Text: This is bad! Sentiment: Negative"
- **Input Text** (orange text):
- "Text: I think the vacation is okay. Sentiment:"
4. **Prompt**:
- Black arrow connecting the dashed box to the "LLMs" box.
### Detailed Analysis
- **Instruction**: Explicitly defines the task (sentiment classification).
- **Context**: Provides labeled examples to guide the LLM’s understanding of sentiment polarity.
- **Input Text**: Represents the user’s query for classification (e.g., "I think the vacation is okay").
- **LLMs**: Processes the structured prompt (instruction + context + input text) to generate output.
- **Output**: Final sentiment label ("Positive" in this case).
### Key Observations
- The diagram emphasizes **prompt engineering** as critical to LLM performance.
- The "Context" section acts as a training example set for the model.
- The "Input Text" box shows an incomplete sentiment label, indicating the LLM’s role in filling it.
- No numerical data or trends are present; the focus is on textual workflow.
### Interpretation
This diagram highlights how LLMs rely on **structured prompts** to perform tasks like sentiment analysis. The inclusion of labeled examples in the "Context" ensures the model understands the task’s requirements. The flow from "Input Text" to "Output" demonstrates the model’s ability to generalize from examples to new, unseen text. The absence of numerical values suggests this is a conceptual workflow rather than a data-driven analysis.