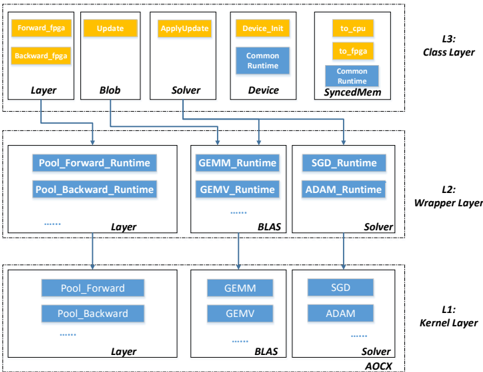
## Architecture Diagram: Neural Network Processing Pipeline
### Overview
The diagram illustrates a multi-layered neural network processing architecture divided into three logical layers: **Kernel Layer (L1)**, **Wrapper Layer (L2)**, and **Class Layer (L3)**. Components are interconnected via directional arrows, indicating data flow and operational dependencies. The architecture emphasizes hardware acceleration (FPGA), runtime optimizations, and solver-based computation.
---
### Components/Axes
#### Kernel Layer (L1)
- **Pool_Forward** and **Pool_Backward**: Basic pooling operations.
- **Solver**: Core computation component (e.g., optimization algorithms).
#### Wrapper Layer (L2)
- **GEMM_Runtime**, **GEMV_Runtime**: General Matrix Multiply and Vector Multiply optimizations.
- **SGD_Runtime**, **ADAM_Runtime**: Gradient descent and adaptive optimization runtimes.
- **BLAST**: Likely a batch processing or data handling component.
#### Class Layer (L3)
- **Forward_FPGA**, **Backward_FPGA**: Hardware-accelerated forward/backward passes.
- **Update**, **ApplyUpdate**: Weight update mechanisms.
- **Device_Init**, **Common_Runtime**: Device initialization and shared runtime environment.
- **SyncedMem**: Synchronized memory management.
---
### Detailed Analysis
1. **Kernel Layer (L1)**:
- **Pool_Forward/Backward** feeds into the **Solver**, which processes gradients and updates.
- Arrows indicate bidirectional flow between pooling and solver components.
2. **Wrapper Layer (L2)**:
- **GEMM/GEMV** runtimes optimize matrix/vector operations, feeding into **SGD/ADAM** runtimes for gradient-based updates.
- **BLAST** connects to the **Solver**, suggesting batch processing integration.
3. **Class Layer (L3)**:
- **Forward/Backward_FPGA** handle hardware-accelerated computations.
- **Update/ApplyUpdate** manage weight adjustments, dependent on **Device_Init** and **Common_Runtime**.
- **SyncedMem** ensures memory consistency across layers.
---
### Key Observations
- **Hardware-Software Integration**: FPGA acceleration in L3 suggests offloading compute-intensive tasks (e.g., matrix operations) to hardware.
- **Runtime Optimization**: Specialized runtimes (GEMM, SGD, ADAM) in L2 indicate modular optimization for specific operations.
- **Hierarchical Flow**: Data flows from L1 (basic operations) → L2 (optimized computations) → L3 (hardware acceleration and updates).
- **Bidirectional Dependencies**: Arrows between **Pool_Forward/Backward** and **Solver** imply iterative gradient computation.
---
### Interpretation
This architecture demonstrates a layered approach to neural network training, balancing software optimizations (GEMM, SGD) with hardware acceleration (FPGA). The **Kernel Layer** handles foundational operations, while the **Wrapper Layer** introduces runtime-specific optimizations. The **Class Layer** integrates hardware and memory management, ensuring efficient end-to-end processing. The use of **BLAST** and **SyncedMem** highlights batch processing and memory synchronization as critical for scalability. The diagram emphasizes modularity, with each layer addressing distinct computational challenges (e.g., gradient computation, weight updates, hardware offloading).