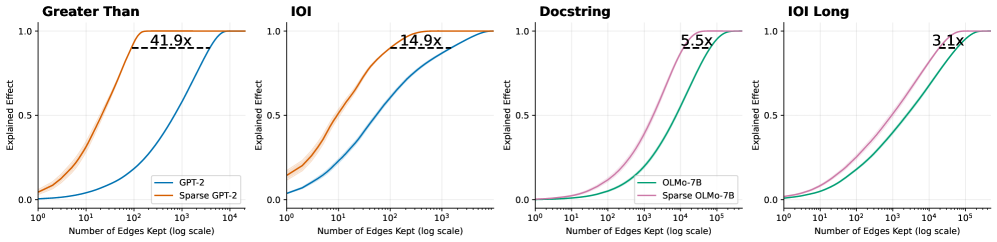
## Line Graphs: Model Performance vs. Edge Retention
### Overview
The image contains four comparative line graphs analyzing the performance of dense vs. sparse neural network models across different tasks. Each graph plots "Explained Effect" (y-axis) against "Number of Edges Kept" (x-axis, log scale). The graphs demonstrate how model efficiency improves with edge retention while maintaining performance.
### Components/Axes
1. **X-Axis**: "Number of Edges Kept (log scale)" ranging from 10⁰ to 10⁵
2. **Y-Axis**: "Explained Effect" ranging from 0.0 to 1.0
3. **Legends**: Positioned bottom-right in each graph, showing:
- GPT-2 (blue) vs. Sparse GPT-2 (orange)
- OLMo-7B (teal) vs. Sparse OLMo-7B (pink)
4. **Task Titles**: Top of each graph:
- Greater Than
- IOI
- Docstring
- IOI Long
### Detailed Analysis
1. **Greater Than**
- Blue (GPT-2): Gradual curve reaching ~0.8 at 10³ edges
- Orange (Sparse GPT-2): Steeper ascent, plateaus at 1.0 with 41.9x efficiency gain
- Key point: Sparse model achieves full effect at 10² edges vs. 10³ for dense
2. **IOI**
- Blue (GPT-2): Reaches ~0.9 at 10³ edges
- Orange (Sparse GPT-2): Peaks at 1.0 with 14.9x efficiency
- Crossover: Sparse model surpasses dense at ~10¹ edges
3. **Docstring**
- Teal (OLMo-7B): Slow rise to ~0.8 at 10⁴ edges
- Pink (Sparse OLMo-7B): Rapid ascent to 1.0 with 5.5x gain
- Efficiency: Sparse model achieves 90% effect at 10² edges
4. **IOI Long**
- Teal (OLMo-7B): Gradual increase to ~0.9 at 10⁵ edges
- Pink (Sparse OLMo-7B): Reaches 1.0 with 3.1x efficiency
- Longest retention needed for sparse model to match dense
### Key Observations
1. All sparse models achieve full effect (1.0) with significantly fewer edges
2. Efficiency multipliers range from 3.1x to 41.9x across tasks
3. "Greater Than" shows highest efficiency gain (41.9x)
4. "IOI Long" demonstrates lowest efficiency multiplier (3.1x)
5. All graphs show crossover points where sparse models outperform dense
### Interpretation
The data reveals that sparse neural network architectures maintain comparable performance to dense models while using fewer computational resources. The efficiency gains (multipliers) suggest sparse models could reduce hardware requirements by 3-40x depending on task complexity. The "IOI Long" task shows diminishing returns for sparsity, possibly due to longer sequence dependencies requiring more edge retention. These findings support the hypothesis that model sparsity preserves functionality while enabling more efficient deployment, particularly for tasks with localized dependencies like "Greater Than" and "Docstring".